
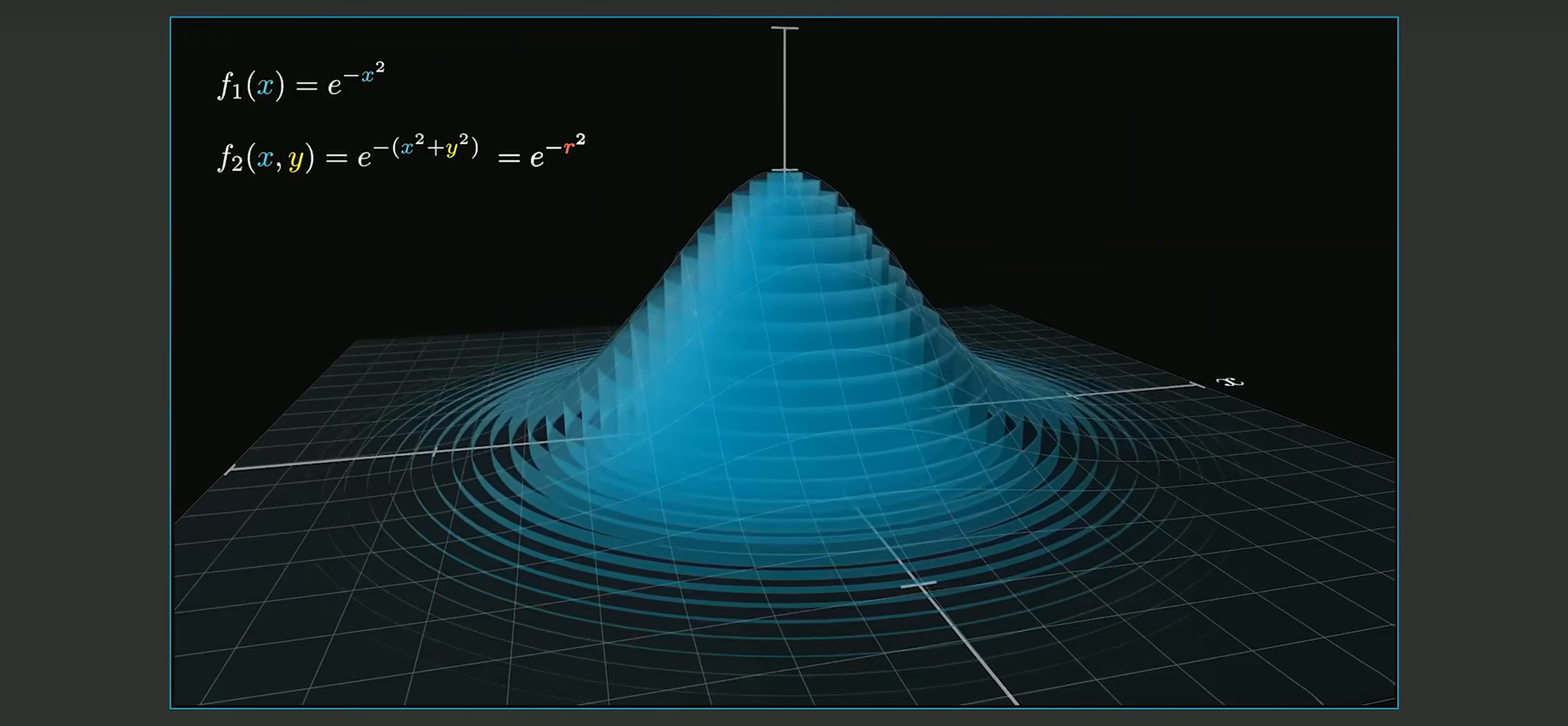
Biostatistics

但很多情况下,我们将自己对事实的判断权无条件地让渡给了一些权威的统计学方法,一味地盲从一些统计学方法中的金标准(例如p值),在这样一种实践态度与行为下学习统计学,只会和统计学越走越远。统计学希望自己能够给你提供一个思考方式,而你却放弃思考,要求统计学直接给你一个答案,这就好像你对你的伴侣百般爱护,而你的伴侣只是馋你的身子,终究是不会有一个好的收场的……
1-概论
用样本统计数对总体参数进行推断——平均数和频率的统计推断、非参数检验、列联分析、方差分析、回归与相关分析、协方差分析。
数据分布特征——集中性、变异程度/离中趋势/离散程度、分布形态。
集中性:数据平均数(算术平均数 + 几何平均数)、位置代表值(众数 + 中位数)。
变异程度:异众比率、极差、平均离差、四分位差、方差与标准差、变异系数。
分布形态:偏度系数、峰度系数。
参数/参量(parameter)是对一个总体特征的度量;统计数(statistic)是根据样本数据计算所得的数值。
分类变量(categorical variable)/定性变量(qualitative variable)/名义变量(nominative variable):变量值定性,表示某个体属于集中互不相容的类型中的一种;另外是定量变量(quantitative variable)/数值变量(numerical variable)-连续与离散。
常数(constant)通常由变量计算而来,只是在一定的过程中保持不变(平均数、标准差、变异系数)。
错误=过失性误差。
准确性(accuracy)与精确性(precision):前者是观测值与真值的差异,后者体现为观测值之间的方差。

2-数据的描述统计
抽样方法:随机抽样、顺序抽样/系统抽样/机械抽样/等距抽样、典型抽样/主观抽样。
- 随机抽样:简单随机抽样、分层随机抽样、整体抽样/整群抽样、双重抽样。
简单随机抽样:适用于个体间差异较小、样本容量较小情况,不适用于具有某种趋向或差异明显或点片式差异的总体。
整体抽样:将整体分为若干群,以群为单位进行随机抽样,对抽到群中的样本做全面调查。适用于不均匀分布的研究对象。抽样误差比简单随机抽样大。
双重抽样:涉及两类变量,是通过观测简单性状去推测复杂形状(难以直接测量的)。 - 顺序抽样:总体最好不要有周期性变异或单调变化趋势。抽样所得样本并非相互独立,只能定性估计抽样误差。无法计算抽样误差、无法估计总体平均数的置信区间。
- 典型抽样:常用于大规模社会经济调查(大总体)。由于主观性而无法估计抽样误差。
处理效应:简单效应、主效应/平均效应、交互作用效应。
- 简单效应:同一因素两个水平度量指标的差。
- 主效应:同一因素内各简单效应的平均数。
- 互作效应:两因素简单效应间的平均差异。n因素互作对应(n-1)级互作。

试验设计的基本原则:重复、随机(
单盲:受试者未知分组;双盲:受试者与测试者均未知分组。
数据整理的相关指标:
- Frequency/Absolute frequency - 频数/次数:即某一分组的数据个数。
- Relative frequency - 频率/比例:样本某一分组频数占样本全部数据的比重。
- Radio - 比率/频率比:任意两个分组之间的比值。
计量数据整理——全距/极差、组数、组距、组中值。
数据特征的定量描述
集中性描述:
- 众数(mode,
) - 中位数(median,
):index( )= 。 - 四分位数(quartile,
):index( )= ,index( )= 。 - 平均数(mean,
或 ):加权平均写法 。 - 离均差:样本中各观测值与其平均数之差,
。 - 离均差平方和(mean deviation sum of square):
,其中a是任意实数。 - 几何平均数(geometric mean,
): ,适用于变量 是对数正态分布或经对数转换后呈正态分布的数据,计算比率平均、反映连年的平均增长率。 - 调和平均数/倒数平均数(harmonic mean,
): ,如果是分组的频率写法则是 。主要反映年度或阶段的增长率/生长率或生长量/规模,容易受极端值影响、偏小极端值明显影响更大。
加权调和平均数是加权算术平均数的“另一种形式”
令
调和平均数是算术平均数的变形使用,差别在二者的变量和权数。算术平均数权数是
对于同一批数据一般有
变异程度描述:
- 异众比率(variation radio,
):分组数据中非众数组的频数占总频数的比率。 。 - 极差(range)
- 平均离差(mean deviation,
): 。 - 四分位差/四分位数间距(
或 ): 。在箱型图中使用——五虎上将之一。 - 方差/均方(variance/mean square,
或 ):对于总体是 ,对于样本是 。样本中的 是自由度( )——一组数据中可以自由取值的个数。取 是因为当平均数确定后, 个数据中只有一个在其他确定后随之而确定、不能自由取值。 - 标准差(standard deviation,
):总体标准差 ,样本标准差 。正态分布情况下, 、 、 。标准差主要用于衡量单样本数据变量分布的比分散变异程度。 - 变异系数/离散系数(coefficient of variability,
): 。变异系数用于衡量二到多个平均数相差悬殊甚至单位不同的样本变量数据的相对变异数(本身是无量纲的)。
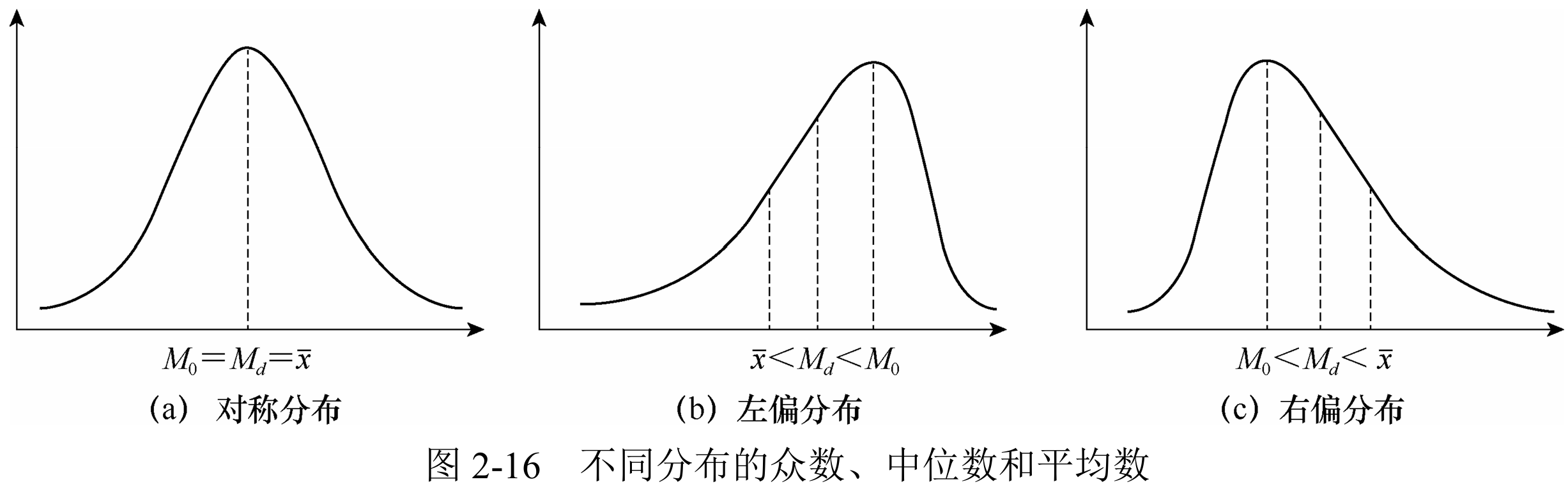
分布形态特征描述
描述变量数据分布的“形状”——对称性、偏斜程度、扁平程度。
- 系数偏度(coefficient of skewness,
):利用众数、中位数和平均数之间的关系大致判断数据分布偏斜的方向,定量计算出系数更加明确—— ,其中 代表组中值,分析一下实际上 是离均差三次方的平均数除以标准差的三次方。 代表对称分布, 右偏、 左偏。若从定量转到定性描述,大于1或小于-1都算是高度偏态分布、在此之内的0.5~1和-1~-0.5都是中度偏态分布。 - 峰度(coefficient of kurtosis,
):这里所谓的“峰”和“平”实际上是与标准的正态分布比较而言的,体现数据在平均数附近的集中程度。 。标准正态分布 , 是尖峰分布,反之为扁平。

3-概率与概率分布
统计是从样本中获取统计数,统计推断是从统计数来推断总体的参数,过程中依赖概率。
大数定律:实际上是用来阐述大量随机现象平均结果稳定性的一系列定律的总称,也是在试验次数充分大状态下将事件A发生的频率(
- 伯努利定理(Bernoulli),即如果
次独立试验中事件A发生了 次,而p是事件A在每次实验中出现的概率。
- 欣钦定理(Khinchine):说明算术平均数与总体平均数在充分大试验条件下的同一性。
离散型概率分布
二项分布
概率分布函数——
概率累计函数:
期望与方差:

从二项分布到多项分布
多项分布是二项分布的直接推广。
二项分布的随机向量只有两个元素,两个元素代表两个对立事件,有各自概率然后进行多次独立试验,二项分布的概率密度图是给定对立事件发生频率的概率
而多项分布的随机向量有多个元素:
上面是在总试验次数下指定次数的概率计算方法,如果是直接指定频率(
适用情形:群体遗传中上一代在经历性选择-繁殖成功率之后推算出下一代各基因型的期望概率,然后计算下一代各基因型期望频率的概率。
泊松分布
当事件发生概率小、样本容量/试验次数大的时候(p小n大,一般以n>20且p<0.05作为近似标准),二项分布转变成泊松分布。
哎呦确实不是很明确,这里放一些书上举的例子罢
显微镜视野中染色体有变异的细胞计数、突变引发的遗传病患者数量分布、田间出现变异植株的计数、作物种子田内杂草的计数、单位容积的饮用水中细菌的数目、家畜产怪胎数、样方内少见植物的个体数等等。
其实就是适合于小概率事件推断。
概率分布函数:
期望与方差:

从二项分布到泊松分布
多少次了,现在算是更懂了。
核心就是,二项分布的本质是0/1分布的叠加,而在一个零一分布的块内,事件的发生概率只能是0、1之间。
而这种失效的情况就主要在出现在预测方面。
总是要举例……
最近7天我乎的阅读总量是
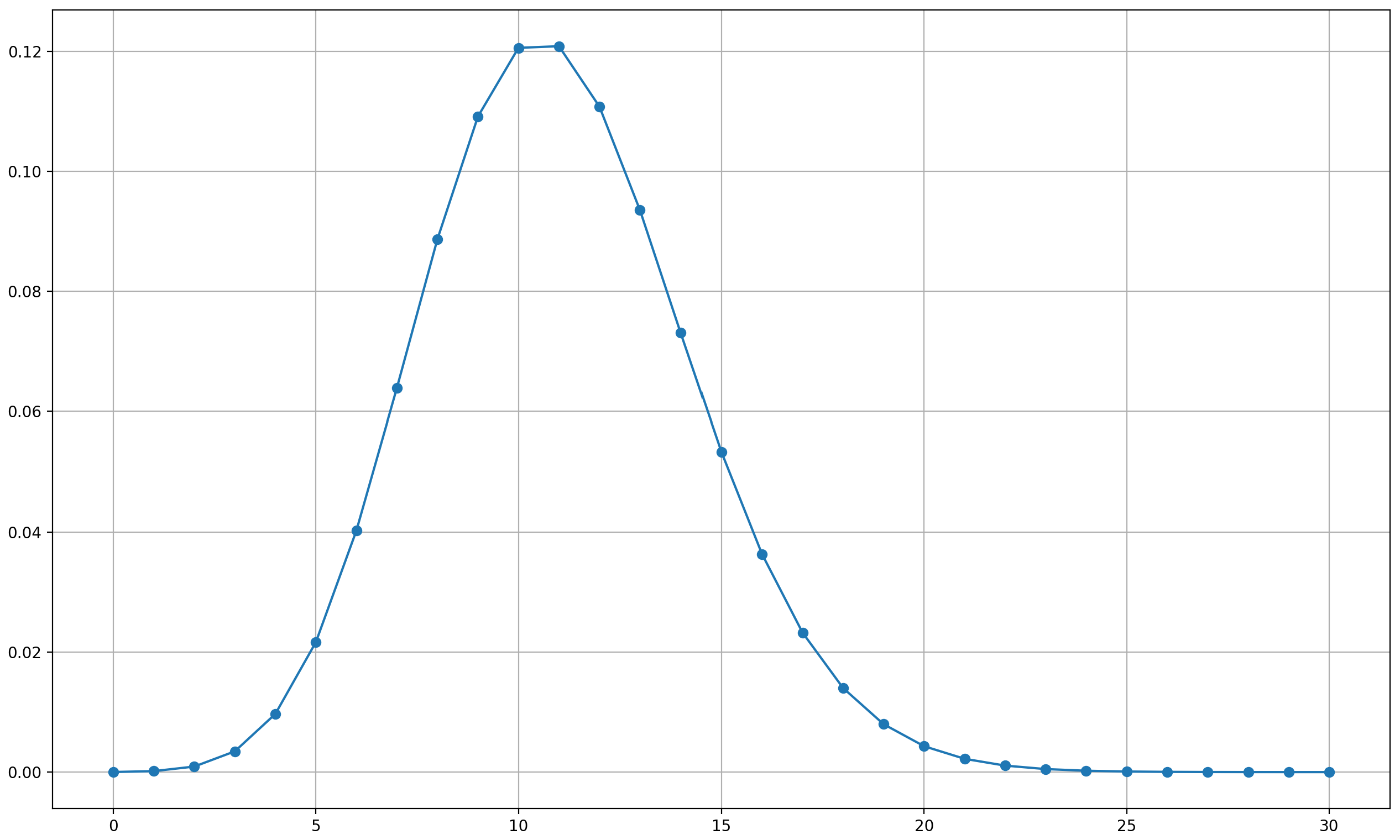
尽管x取值可以到457,但后面的可能性接近于0,为了方便与后面的泊松分布进行图示比较,在此只展示前30的部分。
下周有15个人收藏的概率是
但事实上这种预估的精度并不足够,在天的尺度上,日均收藏量(
数学化的表达就是
由于:
因此泊松公式:
从公式中可以看出,只要确定了
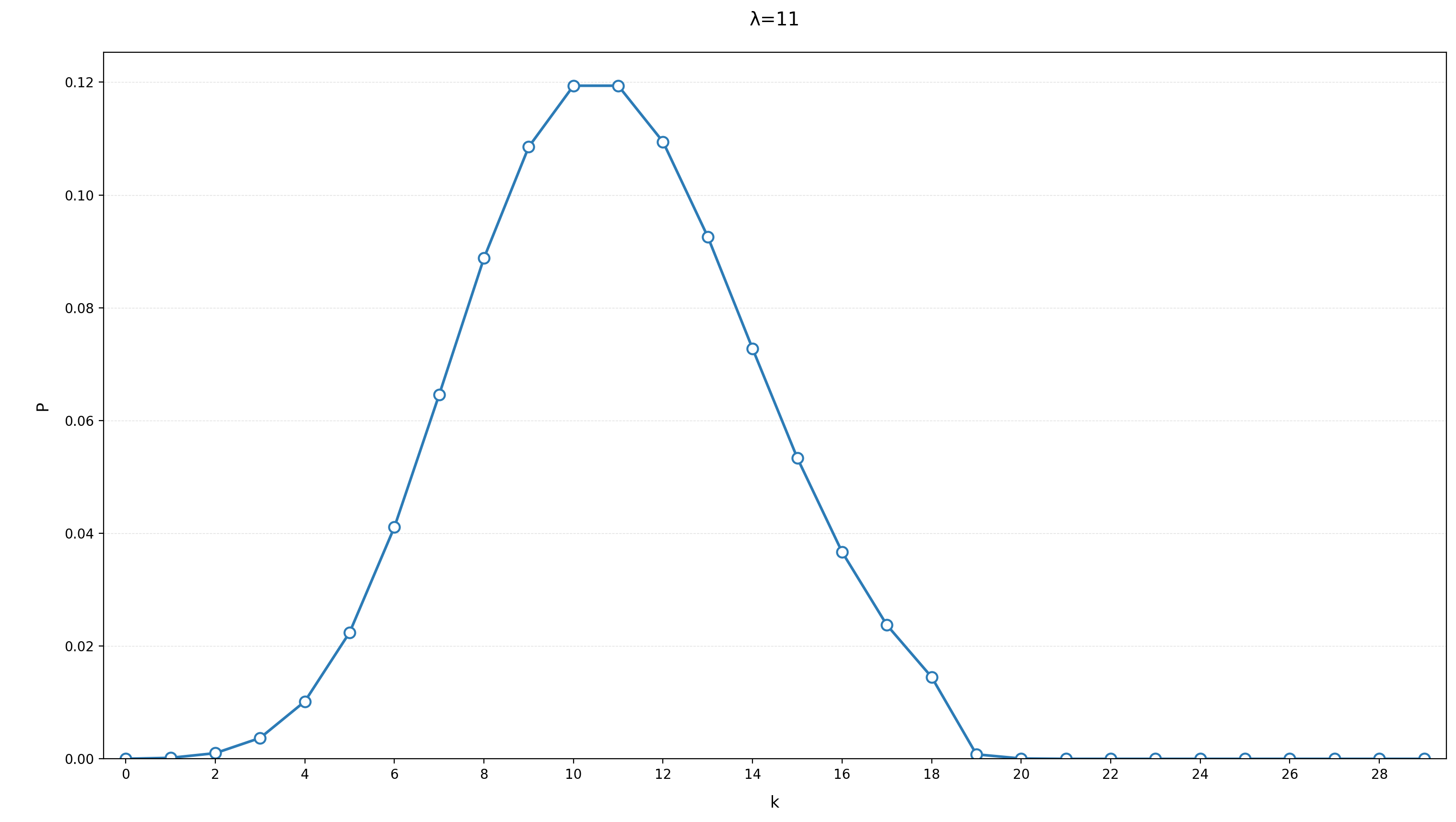
这个时候算出来15个人收藏的概率就是
。会发现概率相差不大。
另外再补充点罢——
- 泊松分布假设单位试验中的平均事件发生率恒定,即
恒定。 - 泊松分布是离散型概率分布,但与连续型概率分布中的指数分布密切相关,如果单位试验发生事件遵从泊松分布,则事件之间的试验次数距离遵从指数分布。
- 当
较小时,泊松分布右偏。随着其增大而会逐渐对称, 时的泊松分布就会逼近正态分布 ,一般在 的时候基本逼近。
关于泊松分布在神经递质释放概率计算方面的应用:受限于尺度,很难计算出神经突触处神经递质量子数量(
连续型概率分布
连续型随机变量主要通过概率密度函数来描述不同范围内取值的概率。
正态分布/高斯分布
据中心极限定理,正态分布由二项分布概率函数在
中心极限定理
中心极限定理实际上是一组定理,一般表述为:对于独立并同样分布的随机变量,即使原始变量本身不是正态分布,随着随机变量数量的增加,许多具有有限方差的独立的且相同分布的随机变量的总和将趋于正态分布。
- 棣莫佛-拉普拉斯定理(De Moivre–Laplace):中心极限定理的最初版本,直接指出“参数为
和 的二项分布以 为均值、 为方差的正态分布为极限”。 - 林德伯格-莱维定理(Lindeberg-Levy):独立同分布、且数学期望和方差有限的随机变量序列的标准化和以标准正态分布为极限。
- 林德伯格-费勒定理(Lindeberg-Feller):是中心极限定理的高级形式,是对林德伯格-莱维定理的扩展,讨论独立的,但不同分布的情况下的随机变量和。它表明,满足一定条件时,独立的,但不同分布的随机变量序列的标准化和依然以标准正态分布为极限。
实际上我一直想知道的是——如何从头推导出正态分布的概率密度函数。
概率密度函数-
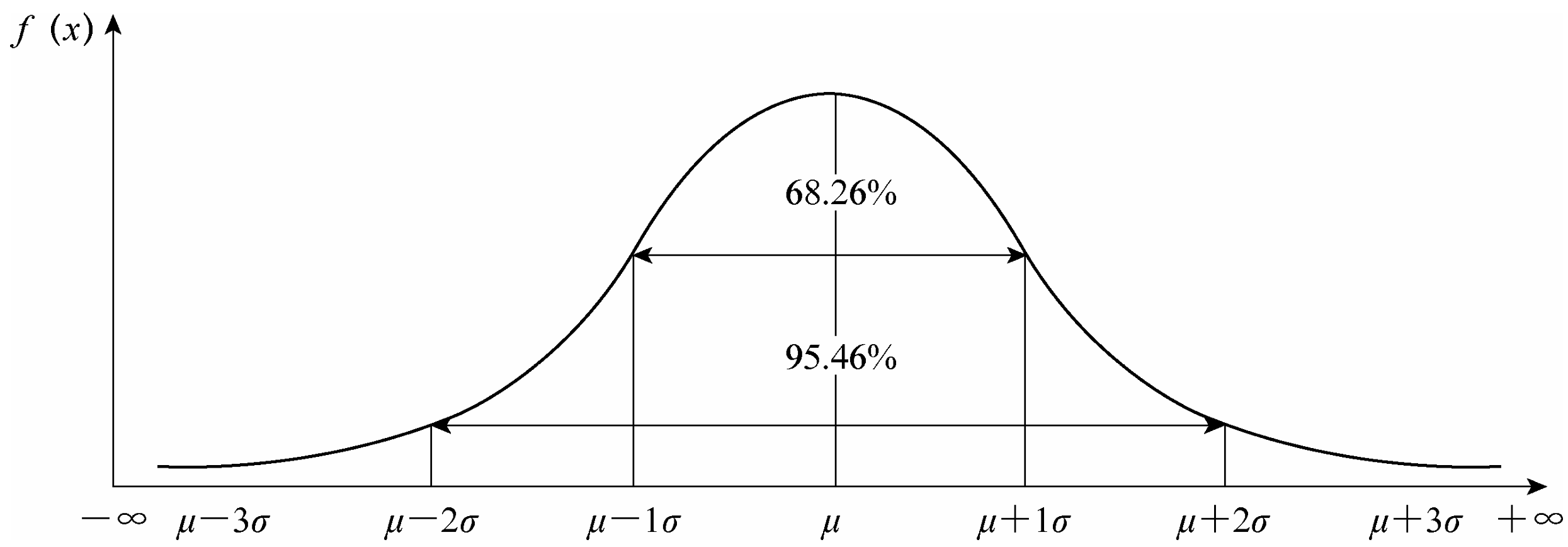
论及图像,正态分布曲线在
关于所谓标准正态分布(
双尾概率:在正态分布中,只有5%的概率(这里的概率是由累积概率分布来的)会
从二项分布到正态分布
你似乎来到了知识的荒原!
关于正态分布概率密度函数里的“
虽然但是,现在学了二重积分其实原因很清楚了。但是这种积分技巧无疑是相当美妙的,于是我依然选择将其记录这里。
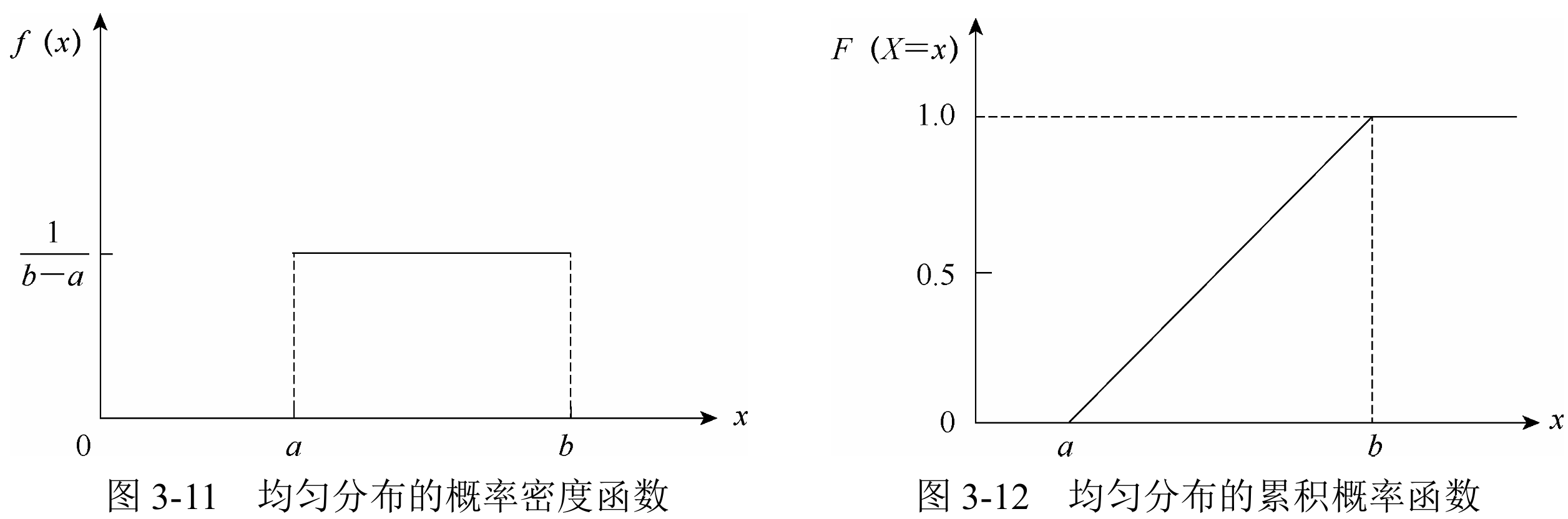
均匀分布
概率密度函数:
期望/均值:
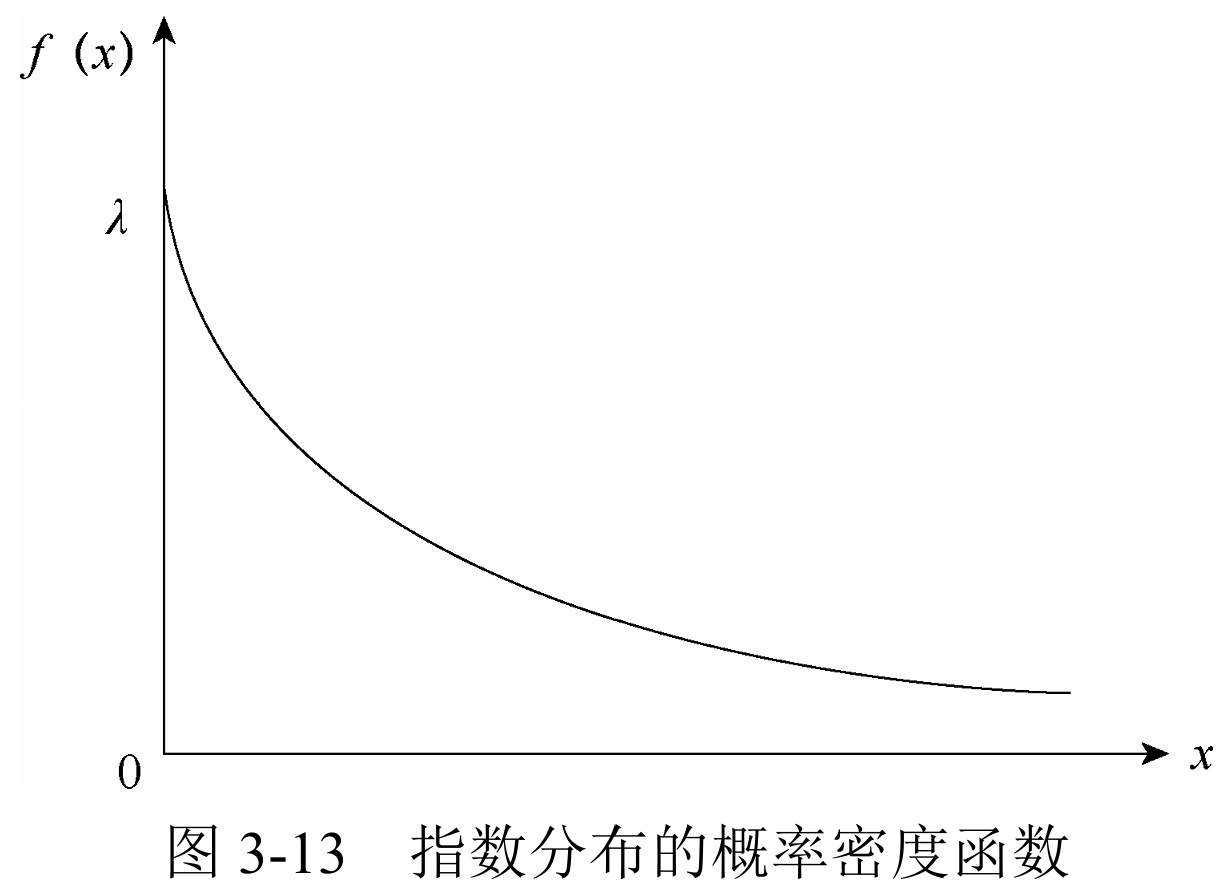
指数分布
指数分布概率分布研究的是泊松过程的事件之间的时间间隔——动植物寿命、微生物繁殖若干倍所需时间。
随机变量
累积概率函数:
期望/均值:
当然可以追求一些深度理解
在对事件之间经过的时间进行建模的时候,倾向于用时间而非事件率来描述模型参数。指数分布中的
从形而上的角度来说,指数分布明显与泊松分布有密切关联,那么指数分布从何而来?
由于研究的是泊松分布中事件发生的时间间隔,那么给定一个“单位时间”,这期间内没有一个事件发生的概率是:一年后猫死了。
那么在一个由
那么反过来想,就有
其实上面就是时间段概率的累加,即一个累积概率函数。进而求一个微分就能得到:猫在
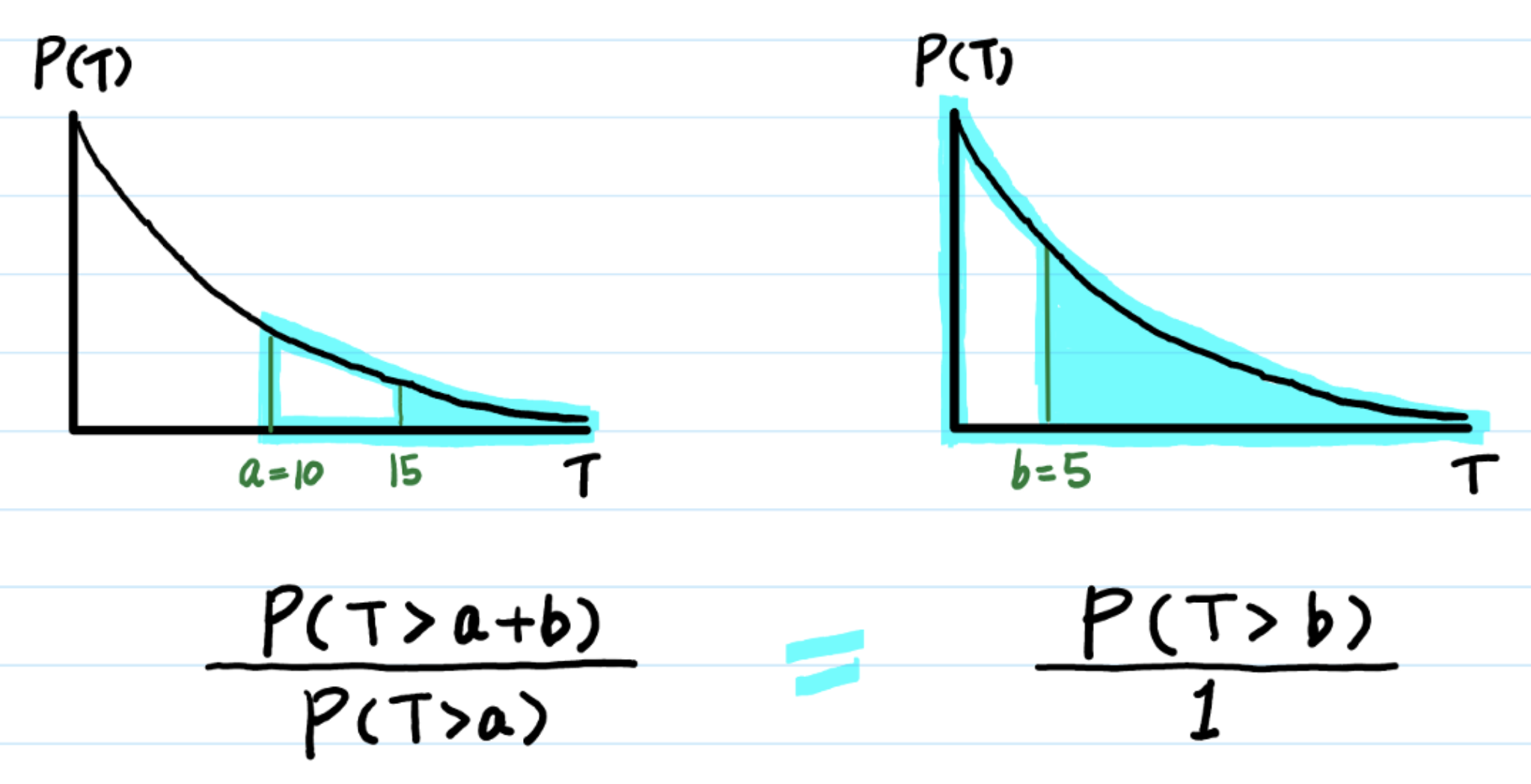
指数分布的一个重要特性——无记忆性:
偶然想到了毕导的视频,放在这里,只是提了一嘴。
风险函数(hazard function):
风险函数在一个大的时间尺度下基于生存函数构建了当前时刻的“风险“大小描述——到
然后结合
然而然而,你会发现前面的kitty寿命的例子明显补兑,因为指数分布没有记忆性,它其实并不适合用于描述生物寿命和机械使用年限,还能活多少年不可能与你已经活了多少年没有关系。
在预测寿命方面,韦伯分布是一个更准确的概率分布模式。
补充
在这里顺便就补充一下另外的两种与伯努利试验密切相关的离散型概率分布,主要是查指数分布的时候拓展到的,内容不多也没啥难的。
几何分布
其实其实,可以把指数分布看作几何分布的连续版。
几何分布(
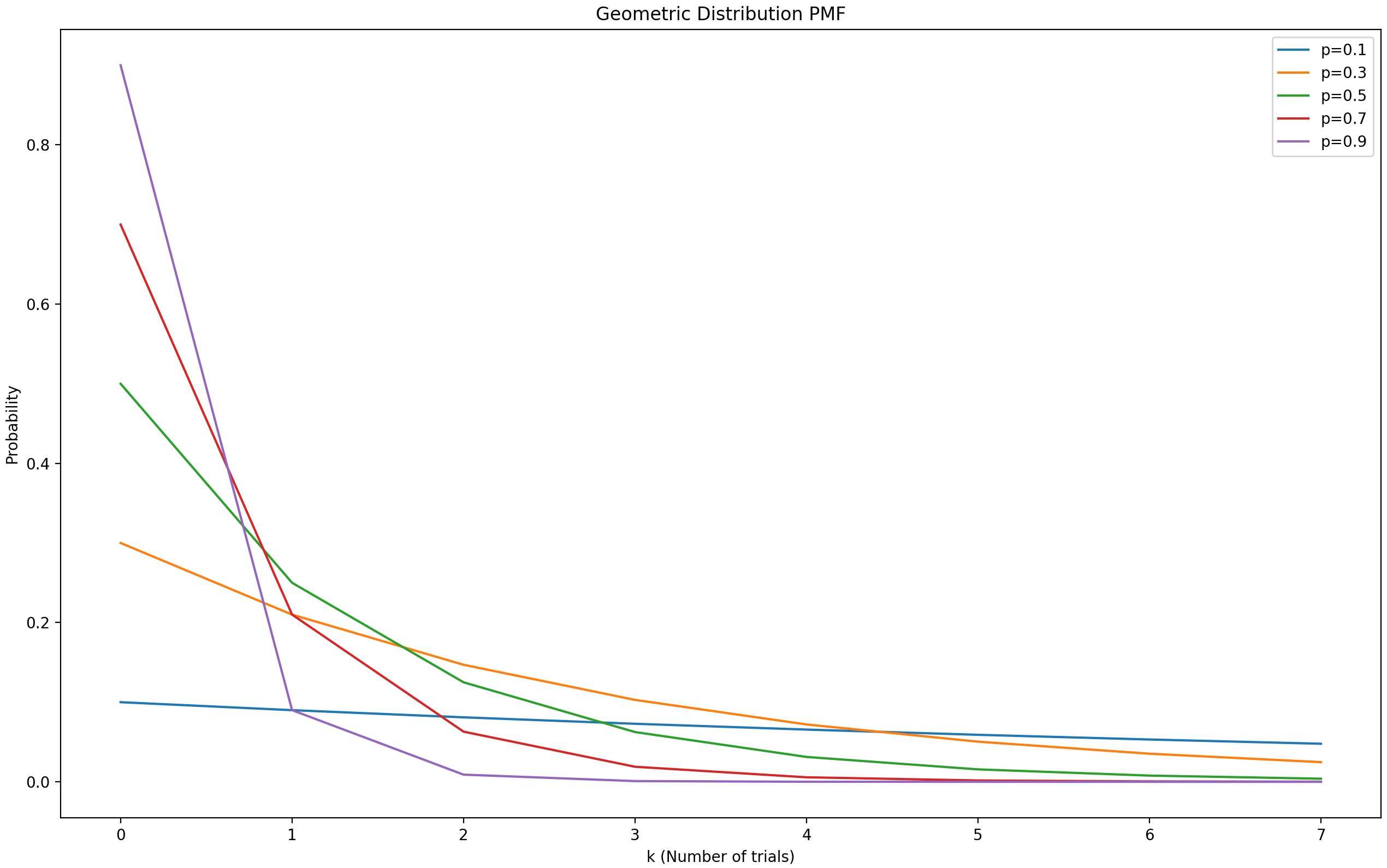
负二项分布
几何分布是负二项分布的一个特例。
负二项分布(
在p保持(
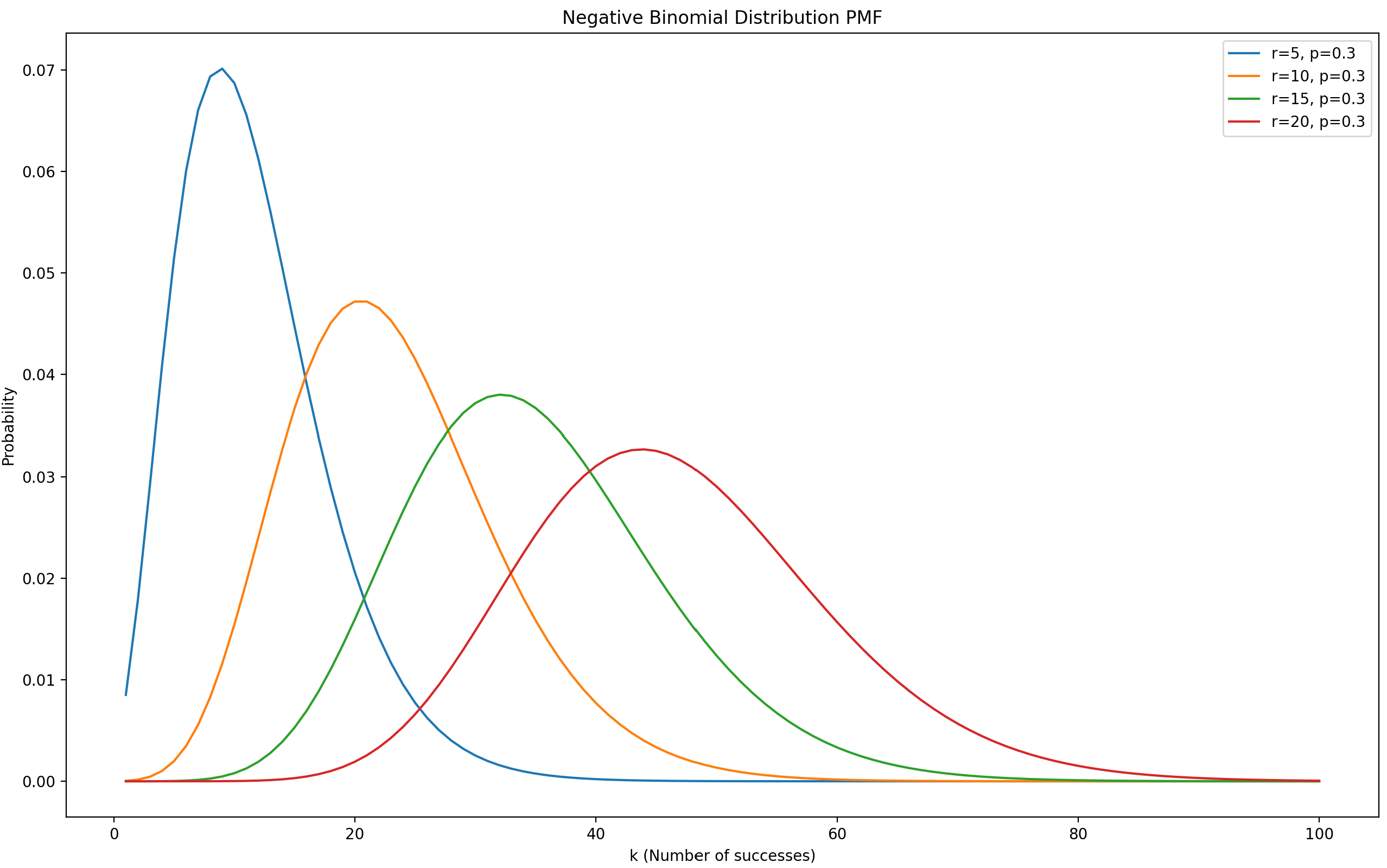
在r要求保持(

韦伯分布
这个是与寿命预测相关的,指数分布来预测生物寿命还是太奇怪了一些。
韦伯分布的概率密度函数为:
其中
:死亡率/故障率随时间而减小。 :死亡率/故障率恒定。 :死亡率/故障率随时间而增大。

均值:
函数:在概率论和组合数学中很常用,是阶乘函数在实数与复数域上的扩展(当 时, ),而当 复数域中时则有 ,其中 (复数 的实部大于零)。
抽样分布
由样本统计数所对应的概率分布叫抽样分布/统计数据分布。对于一个总体,从中抽取样本后每一个样本都可以对其计算一个统计数,而这些统计数的集合就构成一个抽样分布。统计推断的理论基础也就是抽样分布。
若所有可能样本的某一统计数的平均数等于总体的相应参数,那么该统计数是总体相应参数的无偏估计值。
样本平均数的抽样分布
单样本平均数抽样分布
书上例子与计算


样本平均数的平均数与总体平均数相等:
样本平均数的方差与样本大小有关:
中心极限定理(书上表述):如果被抽样整体不是正态总体,但具有平均数
和方差 ,当样本容量 不断增大,样本平均数 的分布也越来越接近正态分布,具有平均数 和方差 。该定理对于连续型变量或非连续性变量都适用。无论总体为何种分布,一般只要样本容量 ,就可以应用中心极限定理,认为样本平均数 的分布是正态分布。 在计算样本平均数出现的概率时,其正态离差
可以按照下式计算: 有点意思,写到正态总体抽样分布没明白 “
不服从标准正态分布” 是啥意思(从单样本中产生的单个统计数为什么说服从某个分布),发现这个正态离差没有讲明白…… 另外有标准正态离差这个概念,就是用来对数据进行标准化处理的,写作
。而在这里的 变成了 ,所谓的 “ 不服从标准正态分布” 指的就是从抽样样本中得到某平均数的概率分布符合正态分布。
双样本平均数差数抽样分布
书上例子与计算

两个样本平均数差数分布的平均数:
从两个独立正态总体(
样本频率的抽样分布
单样本频率的抽样分布
也是样本比例的抽样分布。可以用样本频率(
当n充分大时(
平均数:
双样本频率差数的抽样分布
抽样产生两个大样本进行比较,两个样本频率之差的抽样分布依然可以用正态分布来近似。
平均数:
方差:
正态总体抽样分布
是从正态总体
适用于总体方差
此时
引入统计数t:
期望:
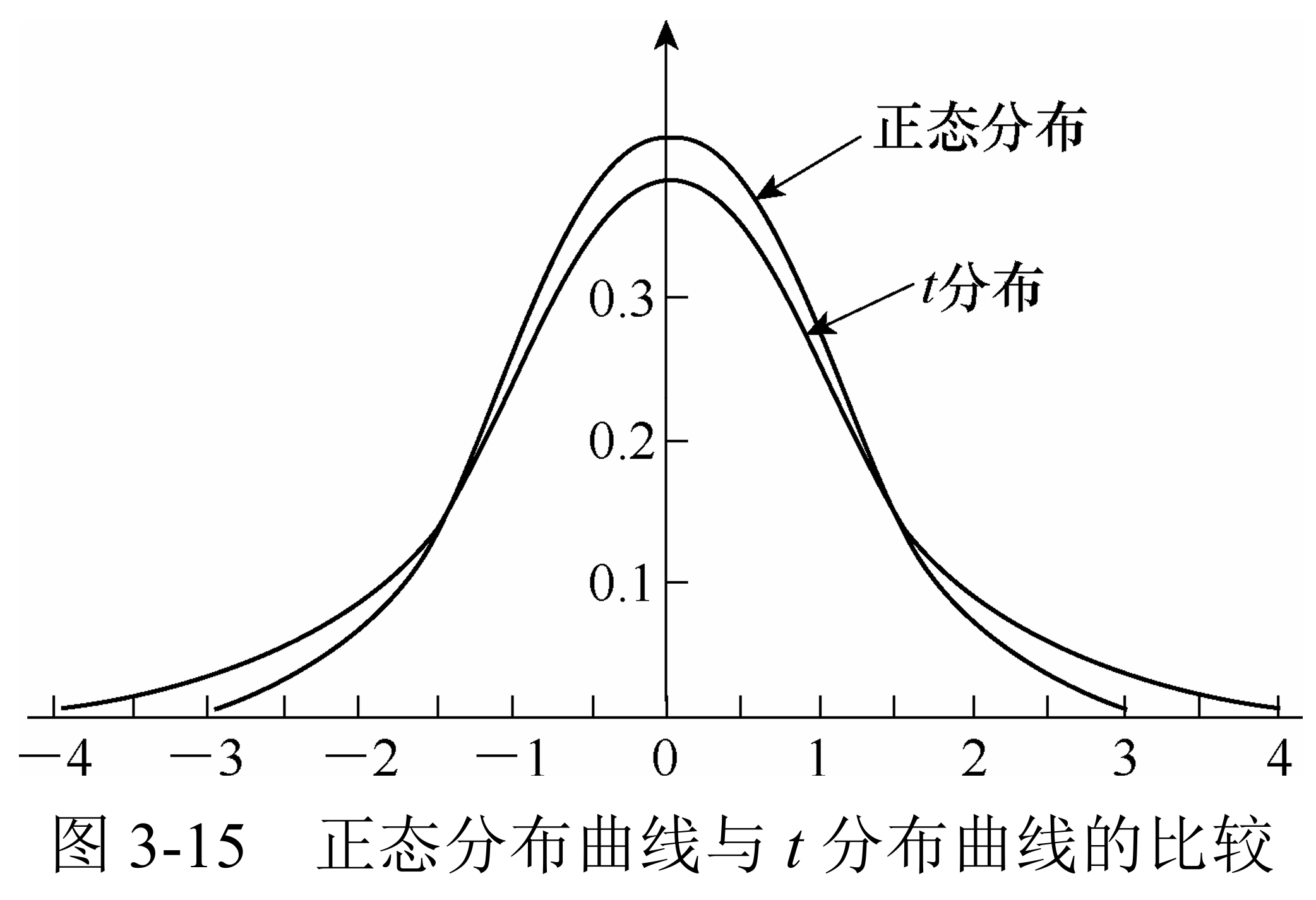
t分布曲线同样左右对称,但相较于正态分布而言具有更高的尾部分布和更低的顶部分布。不同的自由度对应不同的t分布曲线形态,当
假设从标准正态总体(
自由度仍为
和一个显然的概率累积函数:
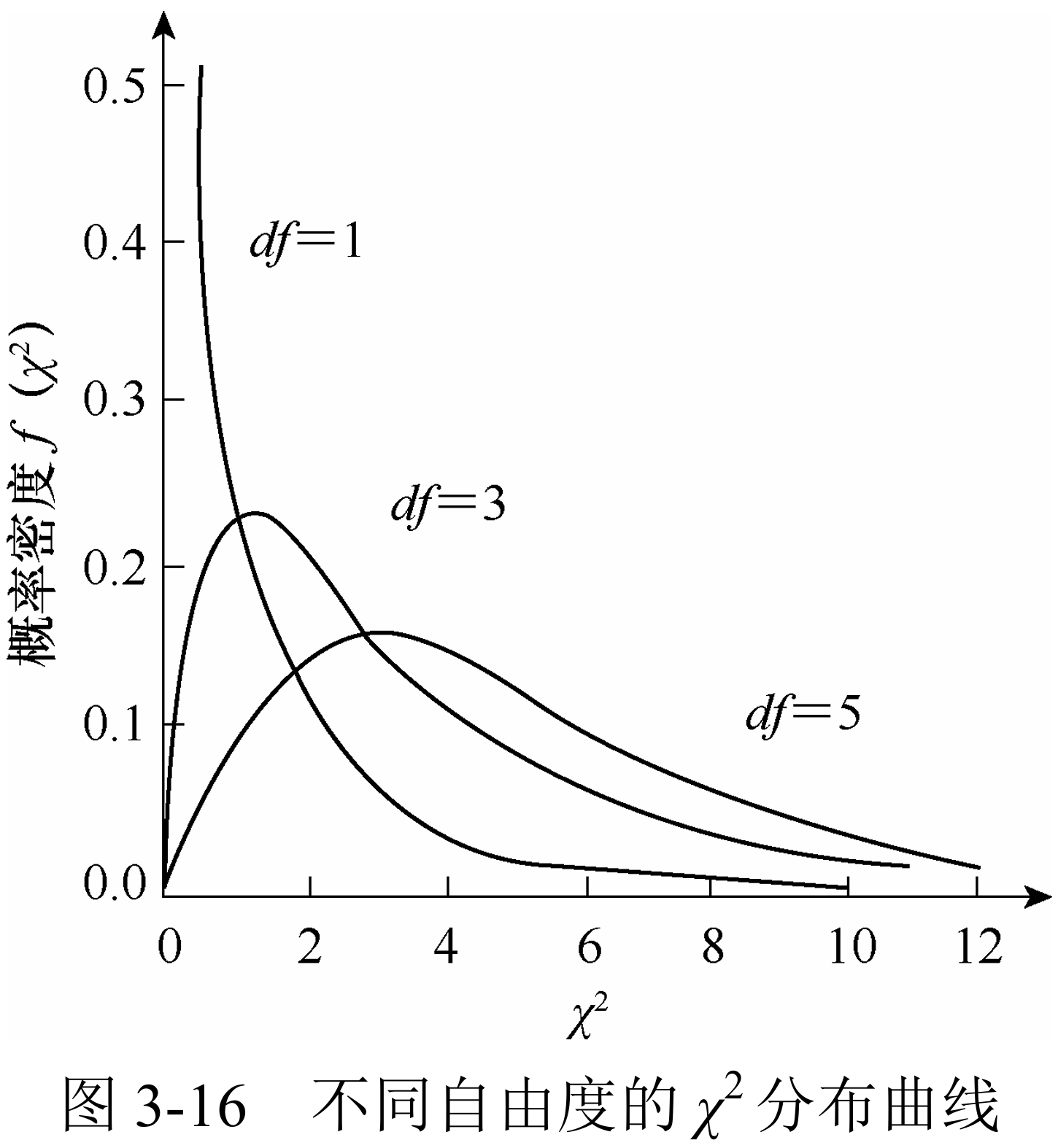
曲线仅分布于区间
同样是从正态分布总体(
再定义
和一个显然的概率累积函数:
平均数:

曲线形态与
4-统计推断
从总体到样本是概率分布,从样本到总体是统计推断。
主要是假设检验/显著性检验(hypothesis test/significance test)与参数估计(estimation of parameter)两个方面。
假设检验的原理与方法
假设检验是根据总体的理论分布和小概率原理,对未知或不完全知晓的总体提出两种对立的假设(无效假设/零假设
“无效”:样本统计数表示的处理效应与总体参数之间没有真实差异,差异来源于随机误差。
样本平均数假设作例
单样本与总体
</div><div class="notel-content"> <p>硅肺病患者群体血红蛋白含量遵从正态分布,平均数$\mu_0=126mg/L$,方差$\sigma^2=240(mg/L)^2$,这些都是总体的数据。</p>用实验药物克矽平治疗六名硅肺病患者,处理后的大小为6的样本具有统计数:
那么就提出
在零假设下,
要判断零假设是否合理,就要看该假设的情形发生的可能性在统计学上是否被接受。
、 ,因此熟识后也可以根据 的大小进行判断。
</div>两个样本相互比较
</div><div class="notel-content"> <p>两个样本来自两个总体,分别有$\bar{x}_1$、$\bar{x}_2$、$\mu_1$、$\mu_2$等数据。零假设是两个样本来源的总体具有同样的平均数($\mu_1=\mu_2$)。</p></div>双尾检验与单尾检验
其实上面样本平均数检验的例子中已经涉及一部分。
根据小概率的显著标准值将整个正态区间划分为三个部分,划分于两个临界值:
单尾就是只有一个否定区,单尾检验查表时需要将双尾概率×2。
若
为 ,则检验的否定区为 ,反之亦然。
两类错误
- 第一类错误 /
错误 / 弃真错误:否定了真实假设(只在否定 时发生),发生这种错误的概率就是选定的概率显著水平 。 - 第二类错误 /
错误 / 纳伪错误:接纳了错误假设(只在接受 时发生)。
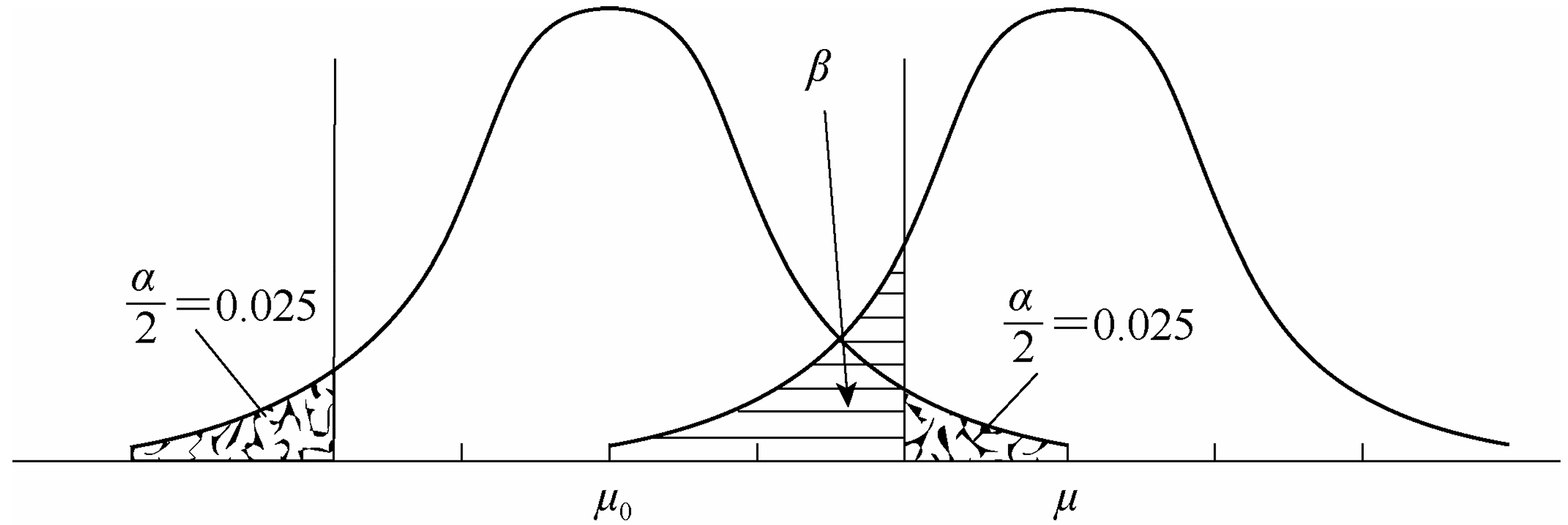
显然选定的概率显著水平不能过高也不能过低,过高导致纳伪错误增加、过低导致弃真错误增加。
有一个假设检验功效/检验效能,表示正确拒绝无效假设
样本平均数的假设检验
单样本平均数假设检验
前文已述,判断样本平均数与总体平均数是否有真实差异的检验。分为总体方差
此时无论样本大小,样本平均数的分布都服从正态分布,进行标准化后服从标准正态分布(
具体例子一张图

这时就要根据样本大小进行抉择。
具体例子两张图
具体操作差不多但是这里还是放图是因为涉及

然后是

双样本平均数假设检验
前文亦已述,检验两个样本平均数(
总体方差
无论俩样本容量多大,样本平均数差数的分布都服从正态分布,用
在零假设情况下(
具体例子一张图

总体方差
与单样本平均数假设检验类似,如果两个样本数量都比较大(
另外一个情况就是只要任一样本数量较小(
成组数据(pooled data)平均数比较的
两个抽样样本彼此独立,都从各自总体中抽取。无论两个样本容量是否相同,所得的都是“成组数据”。以组平均数比较差异显著性。又可以继续细分:
方差同质情况:
检验可以确定两个样本所属总体的方差关系,如果 ,则可以用两个组样本各自的样本方差来对 进行估计(加权计算平均数)—— 。进而计算两样本平均数差数的标准误: ,最后的 服从自由度 的 分布。 方差异质且样本容量相同:
、 。仍然可用 检验(计算流程无异,计算时可以简化出 ),最后计算所得的 应该是服从自由度 的 分布。 方差异质且样本容量不同:此时计算所得
不再服从对应自由度的 分布,只能进行近似 检验。要将两个样本方差都视作总体方差的估计来计算( ),然后是一些近似的校正操作:
具体例子两张图


成对数据(paired data)平均数比较的
要求两个样本间配偶成对,每一对的样本只有一个不同处理、其他实验条件保持一致,可以较大程度控制试验误差、精确度高。
配对设计方法适用情形:两个受试对象分别受两种不同处理(两个受试对象最好也是同一种东西)、同一受试对象接受两种不同的处理、同一受试对象处理前后的自身配对、同一受试对象两个部位给不同的处理。
Note:对于部分成组数据来说,即便两个成组数据的样本容量相同,也不能进行成对数据模式的比较,因为成组数据的每一个变量都是独立的、没有配对比较的基础。成对数据平均数比较的控制变量意味更浓。
不同配对样本间的条件差异可以通过各配对样本差数来消除,假设检验时
设两个样本的变量分别为
样本差数方差:
样本差数平均数标准误有
具体例子一张图


样本频率的假设检验
总体/样本中的个体具有两个“属性”,这些属性在容量中具有对应频率,依照样本中的频率来对总体中的概率进行统计推断的过程就是样本频率的假设检验。进行样本频率的假设检验的基本原理是二项分布,而当样本容量较大、某一种属性的出现频率
单样本频率假设检验
适用于一个样本频率
or :二项分布检验。 , (在 未知的情况下,可以用 的标准误来估计: )。 :二项分布趋近正态分布,检验前需要进行连续性矫正。 用 检验, 用 检验。需要进行连续性矫正的时候, ; 检验参考 时的 分布。 and :不需要进行连续性矫正即可进行 检验。在不需要进行连续性矫正的情况下, 。
具体例子一张图


双样本频率假设检验
类似地,适用于检验两个样本频率(
or :二项分布检验。对于从样本中统计出来的 和 ,可以用两个样本频率差数的方差来估计总体频率的方差和标准误, 、 。 时就有: ,其中 。 :二项分布趋近正态分布,检验前需要进行连续性矫正。 用 检验, 用 检验。需要进行连续性矫正的时候, ; 检验参考 时的 分布。 and :不需要进行连续性矫正即可进行 检验。在不需要进行连续性矫正的 下, 。
具体例子一张图


样本方差同质性检验
其实换个更熟悉的说法是“方差齐性检验”。由于样本平均数和频率的假设检验以样本所属总体方差和总体方差的同质性为基础,在进行假设检验之前进行方差齐性检验十分有必要(有点想吐槽为什么书上不先写这一部分)。
单样本方差齐性检验
此时的
具体例子一张图

双样本方差齐性检验
两个样本进行检验,分别有样本容量
具体例子一张图

参数估计的原理与方法
回望该节最开始的地方,参数估计是与假设检验地位相当的另一个方面(其实是逆过程),但是现在才讲到……
估计量与估计值
- 估计量(estimator,
)是用于估计总体的未知参数 ( ) 的统计数 (Eg: , , ……) :追求无偏性( )、有效性(众多样本产生的无偏估计量中选择标准差小的)、一致性(大样本估计值更加接近总体参数)。 - 估计值(estimated value)是就是某一估计量的具体数值。
参数估计可以分为点估计和区间估计两类,直接以样本统计数作为总体对应参数就是点估计(
参数估计的原理
根据中心极限定理和大数定律,无论总体是否正态分布,样本平均数都近似服从
将括号内改写为
那么区间
单总体参数估计
单总体平均数估计
- 总体方差已知:置信度为
的总体平均数 的区间估计为 。 - 总体方差未知:
- 样本容量
:置信度为 的总体平均数 的区间估计为 。 - 样本容量
:置信度为 的总体平均数 的区间估计为 。 有 。
- 样本容量
单总体频率估计
and :置信度为 的总体频率 的区间估计为 。 or : :置信度为 的总体频率 的区间估计为 。若 未知则可用 替代 。 :置信度为 的总体频率 的区间估计为 。若 未知则可用 替代 。 有 。
双总体参数估计
双总体平均数差数估计
- 总体方差已知:置信度为
的总体平均数差数 的区间估计为 。 - 总体方差未知:
and :置信度为 的总体平均数差数 的区间估计为 。 or : - 成组数据:
:置信度为 的总体平均数差数 的区间估计为 。自由度为 。 、 。 and :置信度为 的总体平均数差数 的区间估计为 。自由度为 。 。 and :置信度为 的总体平均数差数 的区间估计为 。自由度为经过校正的 ,在此不再给出。 。
- 成对数据:置信度为
的总体平均数差数 的区间估计为 。自由度为 。 。
- 成组数据:
双总体频率差数估计
and :置信度为 的总体频率 的区间估计为 。 or : :置信度为 的总体频率 的区间估计为 。 :置信度为 的总体频率 的区间估计为 。 有 。
基于参数估计的样本容量确定
估计总体平均数时样本容量
- 估计单总体平均数时样本容量:在总体方差
已知的情况下,总体平均数 的 置信度置信区间为 ,可以进一步改写为 。因此如果给定预期估计误差为 (单方向的误差),那么可以求出估计的样本量 。 - 估计双总体平均数时样本容量:置信区间的估计误差部分可能有两种情况——
(总体方差已知或均为大样本) 和 (总体方差未知或存在小样本)。因此有两个限制,两个样本容量应该一样大( )、总体方差应为已知。此时再给定一个估计误差 ,可以推算出样本容量: 。
估计总体频率时样本容量
- 估计单总体频率时样本容量:
时的估计误差为 , 且 时的估计误差为 。明显在给定置信度和估计误差 的情况下都是可以计算出 的,只是相对来说前者会更好算一些,这里给一下: 。 - 估计双总体频率时样本容量:和前面出于基本一样的原因,尽管假设检验中情况多种多样,但求出样本容量的要求就比较苛刻了(要求两个样本容量相同,还有不出现
分布的前提,下面已经提前处理掉了)。 且 时估计误差为 , 且 时估计误差为 。虽然都可以算但还是前者容易算一些,这里给出: 。
5-非参数检验
参数检验与非参数检验的显著区别就是,参数检验是在明确知道(给定或能明确假定的)总体分布的情况下进行的,检验的主要任务是用样本统计数来对总体参数进行估计/检验。
那么与之相对,非参数检验(nonparametric test)/任意分布检验(distribution-free test)可以在不考虑总体参数和总体分布的情况下,从数据本身来获得所需要的信息(对样本所代表总体的分布/分布位置)进行假设检验。
非参数检验几乎可以处理包括分类数据和顺序数据在内的所有类型的数据,参数检验通常只能用于定量数据的分析。如果数据明确具有进行参数检验的条件再来用非参数检验的话会导致检验功效下降、易犯II类错误。
游程检验
目的:检验样本独立性,确定重复出现的变量值随机。理论基础是二分类序列或类型出现顺序的随机性问题。
游程检验(run test)/连贯检验(coherence test)/串检验(strings test)是一个典型的针对二分变量样本标志表现排列所形成游程的多少进行判断的检验方法,可用于判断观测值的顺序是否随机。
游程:对于可以二分的总体,样本分为两类后,其中一类符号连续出现的“段”就叫游程(
对于一个经典的抛硬币伯努利试验,在变量序列中正反面的交替不会太频繁但也不会太少。对于结果序列,其中正面1反面0的出现频数与游程数和概率有关,如果已知出现频数则与概率无关了。给定试验次数的情况下,游程数与游程长度明显有负相关,交替太频繁认为“混合”、交替太少认为是“成群”。
游程检验的流程
建立假设
游程检验的统计数就是又称个数
在给定的
对于普通的伯努利试验来说,预期显然是
于是可以根据上面的式子计算给定某个
、 均不大:查询游程检验表直接推断。不同 、 、 都会产生对应临界值 、 。 、 均较大:样本容量大,若零假设成立则由“精确分布”的性质,可以借用正态分布表得到具体的 值。对于 和 的正态分布有如下参数估计——
具体例子两张图



符号检验
在总体未知且样本小的情况下,可以将原始观测值“按照设定的规则”转换为正负号(设定某一标准进行二分),对正负号统计个数以进行检验。很自然地会想到对样本数据进行相对总体中位数的处理,那么显然理论上产生的符号序列中符号个数的分布应该服从
具体使用中的符号检验表就是不同
具体例子一张图


上面给的是单样本的符号检验,但实际上即便对于两个配对样本,其符号检验都没有太大差异。后者的
秩和检验
符号检验具有一个明显缺点,即忽略了观测值与
原理与方法
秩/秩次:数值变量由小到大、等级变量由弱到强所排列的序号(
秩和:用秩次替换原始数据,按某种顺序排列的序号之和即为秩和。例如将样本容量分别为
- 计算
产生距离序列; 个绝对值排序,对应 个秩,若有相同距离则取平均秩次; ( )、 ( )。有 ,就是前面换了个表达。 - 双尾检验的
应表现为 , 为 。检验统计数取为 。单尾检验的 为 、 为 ,vice versa。 - 根据
值直接查 符号秩检验表,确定特定显著水平 下否定 的临界 值。
当较大时可以用正态近似,“得到一个与 有关的正态随机变量 的值,再查表得到对应 值”。
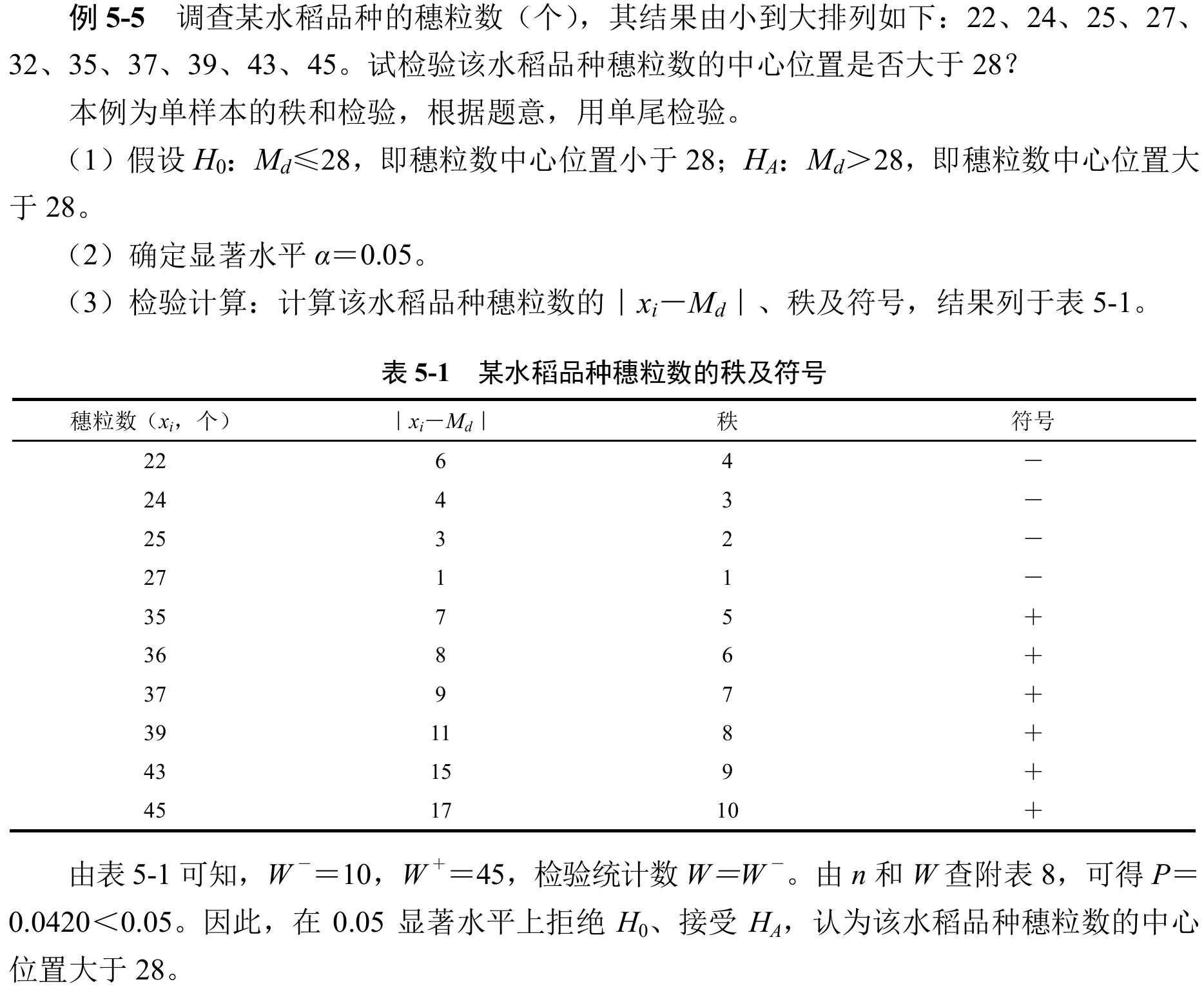
单样本秩和检验
具体例子一张图
双样本秩和检验
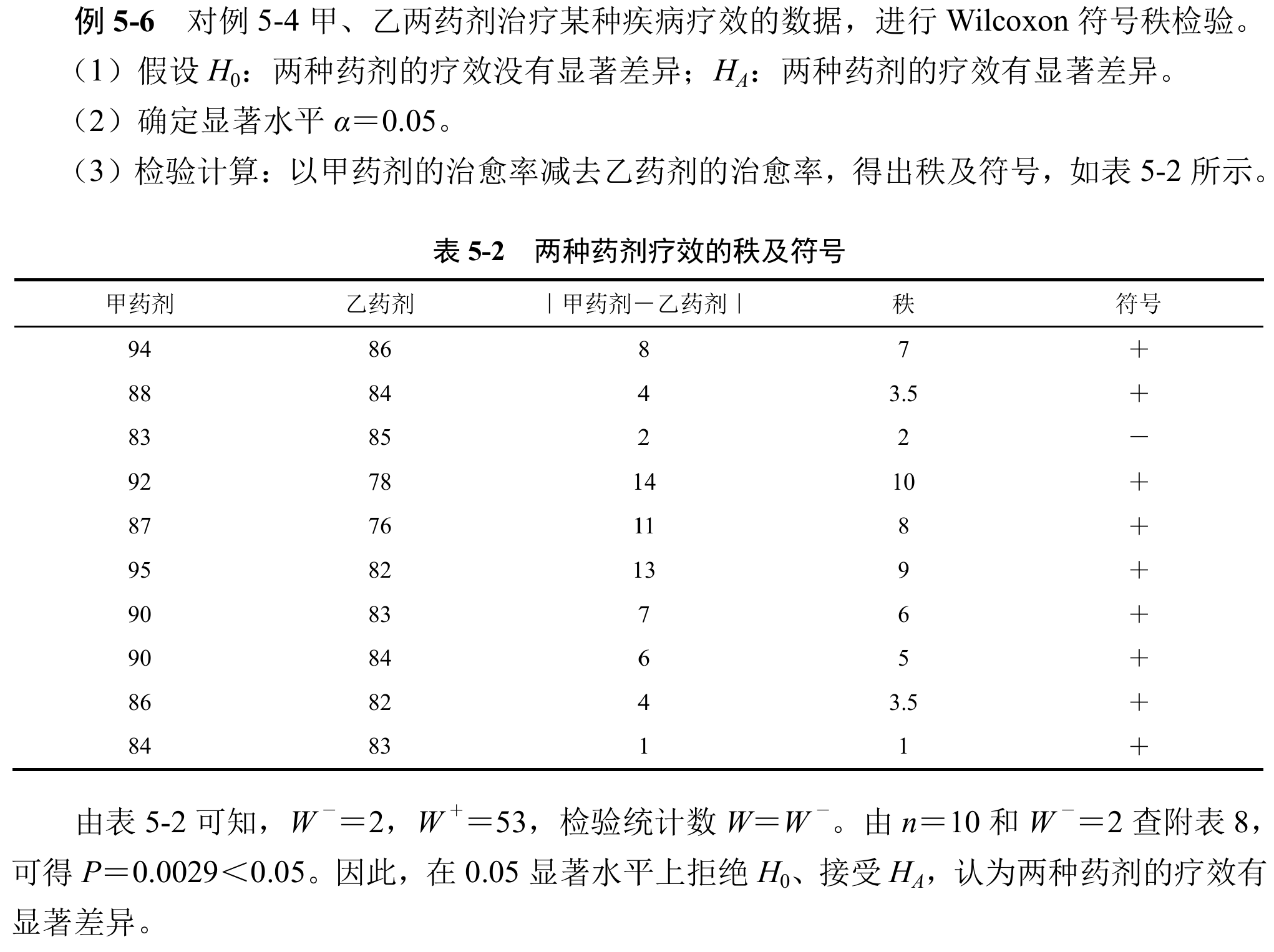
成对数据秩和检验
由于数据成对(paired),检验两个样本中位数是否相同其实等价于对两组数据做差处理,对差值检验
具体例子一张图
两个独立样本秩和检验
Brown-Mood中位数检验:两个样本容量不同,没有配对关系、相互独立(
与 )。对应的两组样本 和 分别有总体中位数 和 , 为 ,此时将两组样本混合产生序列中位数应该有 关系。检验过程涉及 列联表过程(与 相同的观测值可以忽略掉,或者随机放在任意一边),具体原理将在第6章中涉及。 
设
是 样本中大于 的变量,则 的分布在 时表现为超几何分布( 、 ):
在进行判断的时候遵循以下原则:针对不同的样本大小需要进行一些调整↓
大样本在无效假设时可用超几何分布的
标准正态近似性进行检验,对应地有判定 值的 值: 小样本必须进行连续性校正:


具体例子一张图

Whitney-Mann-Wilcoxon秩和检验:类似于单样本Wilcoxon秩和检验,相较于只看符号的Brown-Mood中位数检验也看了两样本具体观测值的相互关系。检验目的是看两个样本是否来自同一总体。
那么类似的过程,混合两个样本并按顺序排列,形成新的秩。而回到两个样本就有各自的秩和,将
和 称为Wilcoxon秩和统计数。进一步地有 or (Mann-Whitney统计数)——前者表示 样本观测值大于 样本观测值的个数,后者类推。 时的两个Mann-Whitney统计数应具有相同的分布。有关系式如下↓ 然后就可以直接根据M-W统计数来查表判断是否接受假设了。
依然有一些调整↓
且 :此时的秩和 分布接近正态分布,可以计算相关参数(平均数、标准差)进行模拟。而一般的W-M-W秩和检验主要适用于 和 的情况。 如果存在“并列数据”,则需要进行近似
检验,此时对标准差进行校正: 是并列秩次数据 的函数。
具体例子一张图


又称“Kruskal-Wallis秩和检验”。
适用于不满足正态分布或方差异质的二至多样本比较,定义有检验统计数
当不同样本间具有较多相同秩次的变量时,估计的
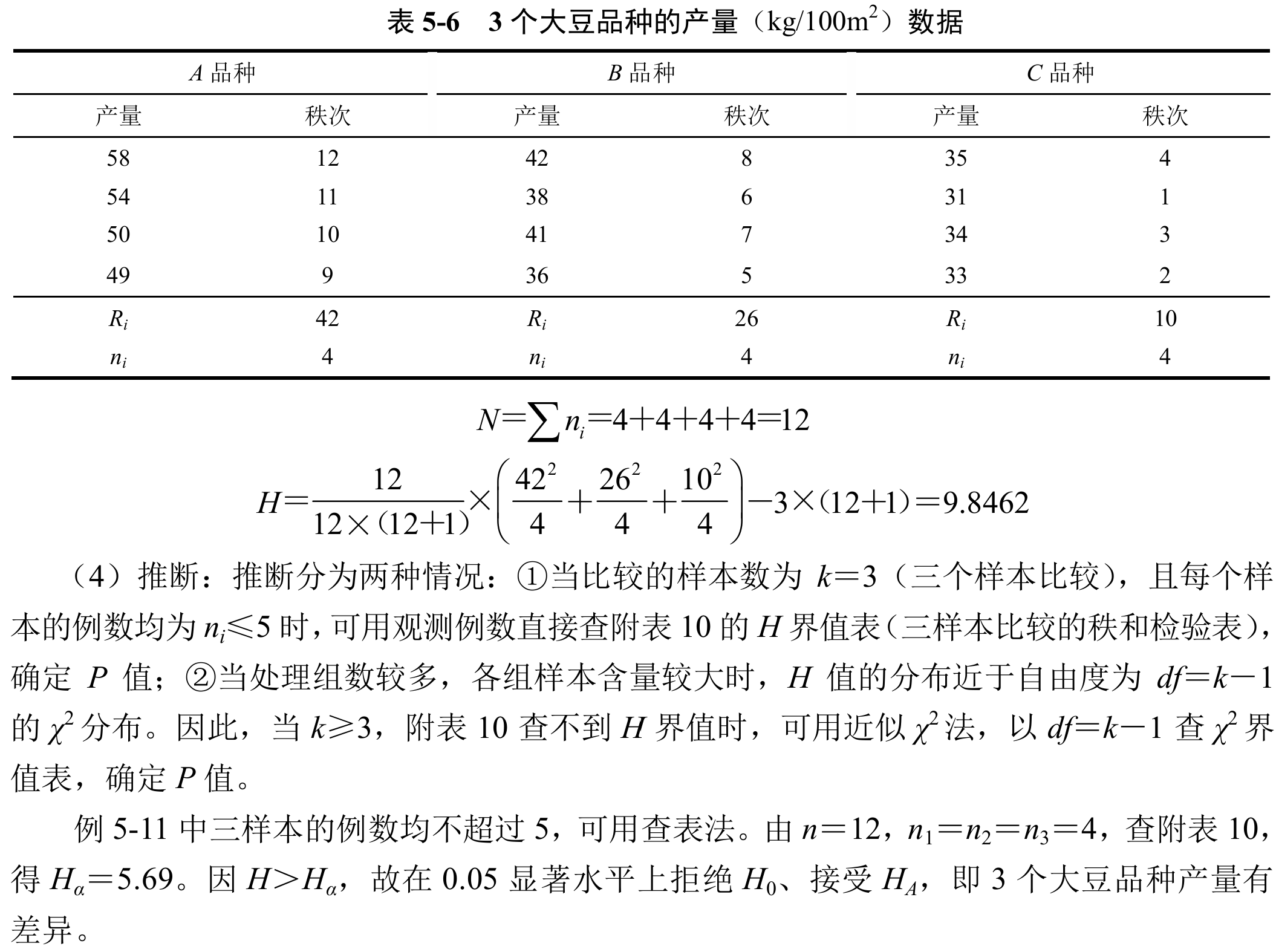
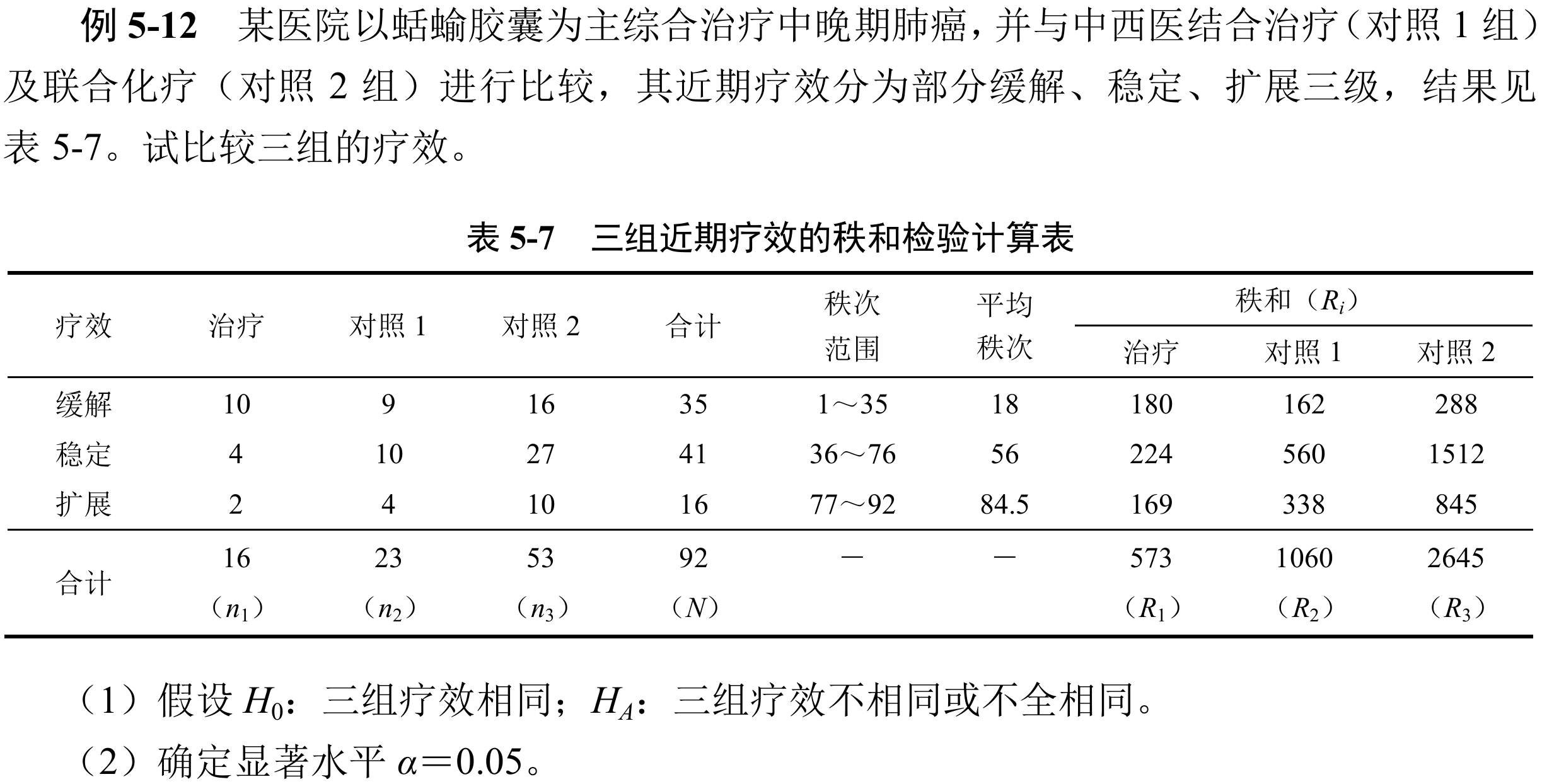
原始数据多样本比较的秩和检验
具体例子一张图
注意多组、各组样本容量大情况下近似

频数表数据多样本比较的秩和检验
流程基本与原始数据多样本比较的秩和检验类似,两个注意点:
- 同一组段或等级的值一律取平均秩次,再用各组段的频数加权。
- 由于用频数统计,因此相同秩次会比较多,注意用上面提供的校正公式对
进行校正。但如果能根据 直接拒绝 ,则不用去计算校正值 。
具体例子一张图

6-列联分析
列联表与χ²统计数
列联表用于处理离散的分类数据,是一种由两个以上的变量进行交叉分类的频数分布表,本质是挖掘行向量组(

列联表分布涉及观测值(
而如何对期望值和观测值之间的差异进行定量的统计学判定,需要回顾一下之前的
对分类数据进行
检验,其基本原理是应用观测值与理论值之间的偏离程度来决定其 值的大小。
因此在列联表的分析中
检验流程一如既往。提出零假设备择假设→确定显著水平→计算
Note!由于
任何一组的理论值
都必须大于5。如果有 的情况,务必并组或增大样本容量。 自由度
时需要进行连续性矫正,矫正后的 会比原来小:
拟合优度检验
拟合优度检验/适合性检验/吻合性检验,就是上面对观测值与理论值是否存在差异的假设检验。
在遗传学基因型比率表现中很常见,下面给出一些预制菜:

对于数据组数多于两组时,还可以用简式
独立性检验
零假设为行向量组影响与列向量组无关,假设各类别之间没有关联。根据显著水平查表判定机械流程。
列联表结构中,独立性检验的自由度有
2×2型

2×2型中必定涉及连续性矫正,简式计算有:
2×C型
给出不用计算中间理论值的简式:
R×C型
给出不用计算中间理论值的简式:


Fisher精确检验与McNemar检验
Fisher精确检验
基于2×2列联表分析,检验两个分类变量是否独立,可精确P值,适合于小样本检验或理论频数非常小情况。表述的是在边际总数不变的情况下,出现使用当前分类处理分配模式的可能性大小。
具体例子
没办法书上常举具体例子来说事,实际上并不是很喜欢。然而又不想让过于实际的事例直截地出现在文档中,因此就只好在该folding下面展开说说了。
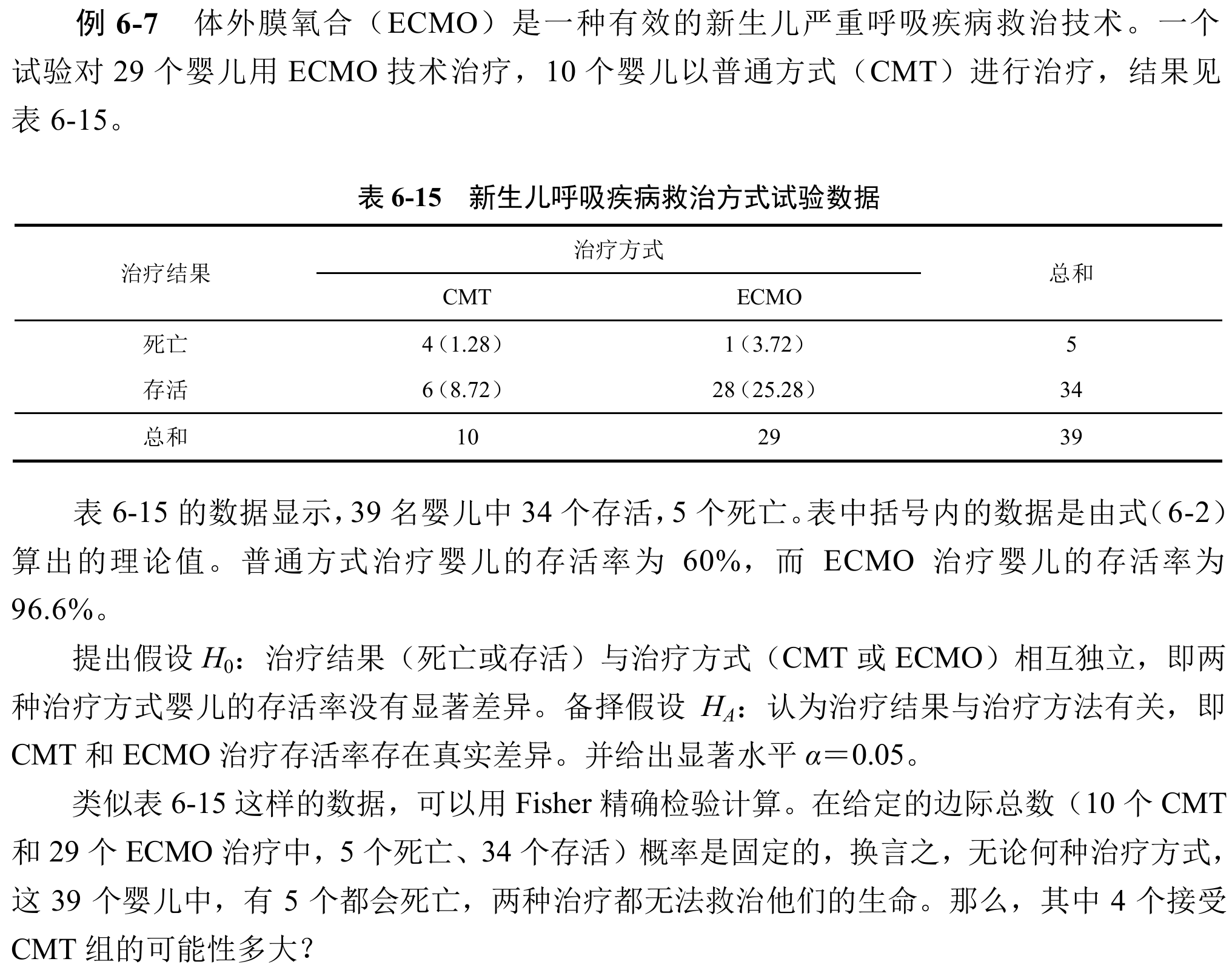
此时进行检验用的是二项式分布,直接计算总取样方法和指定分类取样方法数量比就可以了。
从5个死亡的婴儿(婴儿死亡数目就是这个例子下的“边际总数”)中选4个进到CMT组的方式数是
、存活的34个婴儿中选出6个进到CMT组的方式数是 ,从39个婴儿中选出10个进入CMT组的方式数是 。最后计算有 。
什么你问我为什么写的是
而真正的
至于Fisher精确检验与
检验是基于 分布的,当样本容量很大时,这种分布就为 检验的理论抽样提供了比较好的近似值。但是,当样本容量比较小时,这个近似值就不太可信,从 检验得到的P值可靠性也就降低了。
McNemar检验
又称“非独立样本频率/比率的
在2×2列联表上更改为对立事件是否发生作为计数对象,此时的事件构成总体可以用二项分布进行描述。而McNemar检验是对二项分布“非此即彼”事件结果发生概率所进行的
此时用于假设检验查表的统计数是:
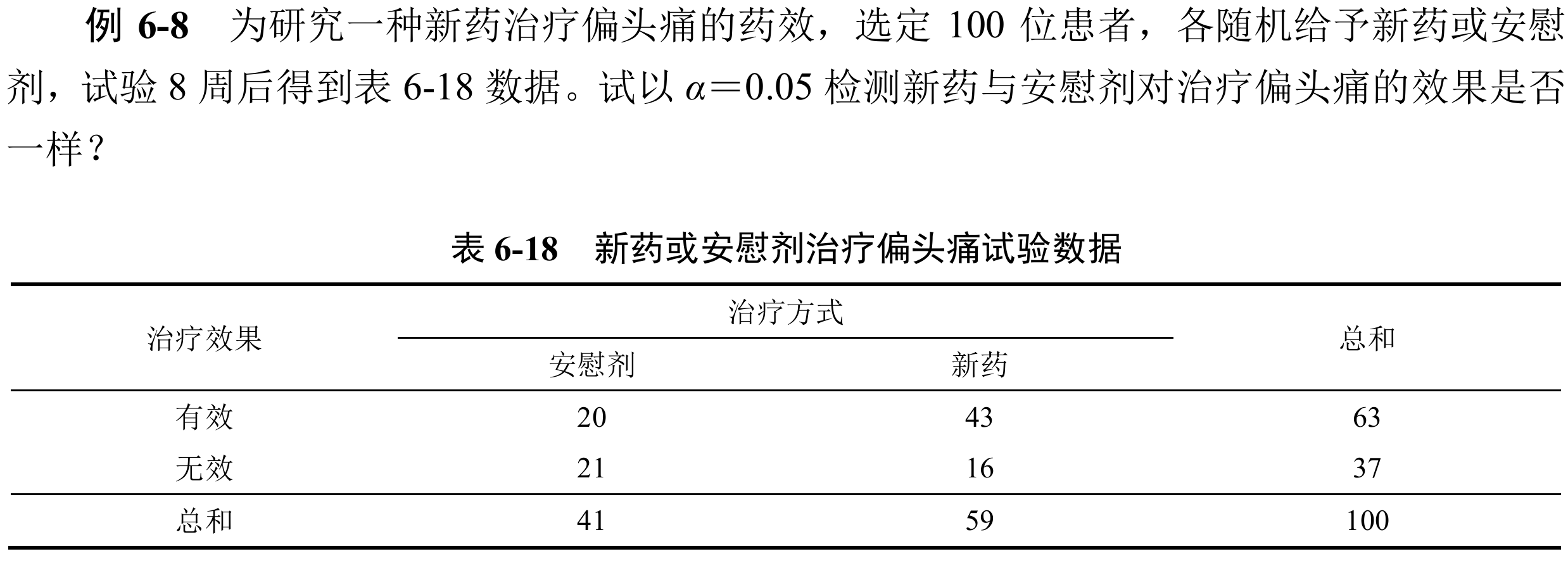
具体例子一张图

列联表中的相关系数
φ相关系数
当
列联相关系数
又称“
局限在只能对比相同行与列的列联表。
V相关系数
差分概率的置信区间与相对风险
差分概率的置信区间
2×2列联表的
对于一个标准的2×2列联表:
| 处理1- | 处理1+ | |
|---|---|---|
| 处理2- | ||
| 处理2+ | ||
定义:
则标准误:
置信区间:
相对风险与比值比
相对风险/风险系数:
比值比(
7-方差分析
基本原理
基本思想
方差分析/变量分析(ANOVA),是对二至多样本平均数进行差异显著性分析的统计方法。当然不仅仅是对多样本平均数进行比较,ANOVA还可以分析多个因素间相互作用、回归方程的假设检验、方差的同质性检验。方差分析把观测值变异原因分解为处理效应与误差效应。
数学模型
以k个水平、n次重复的单因素实验为例:
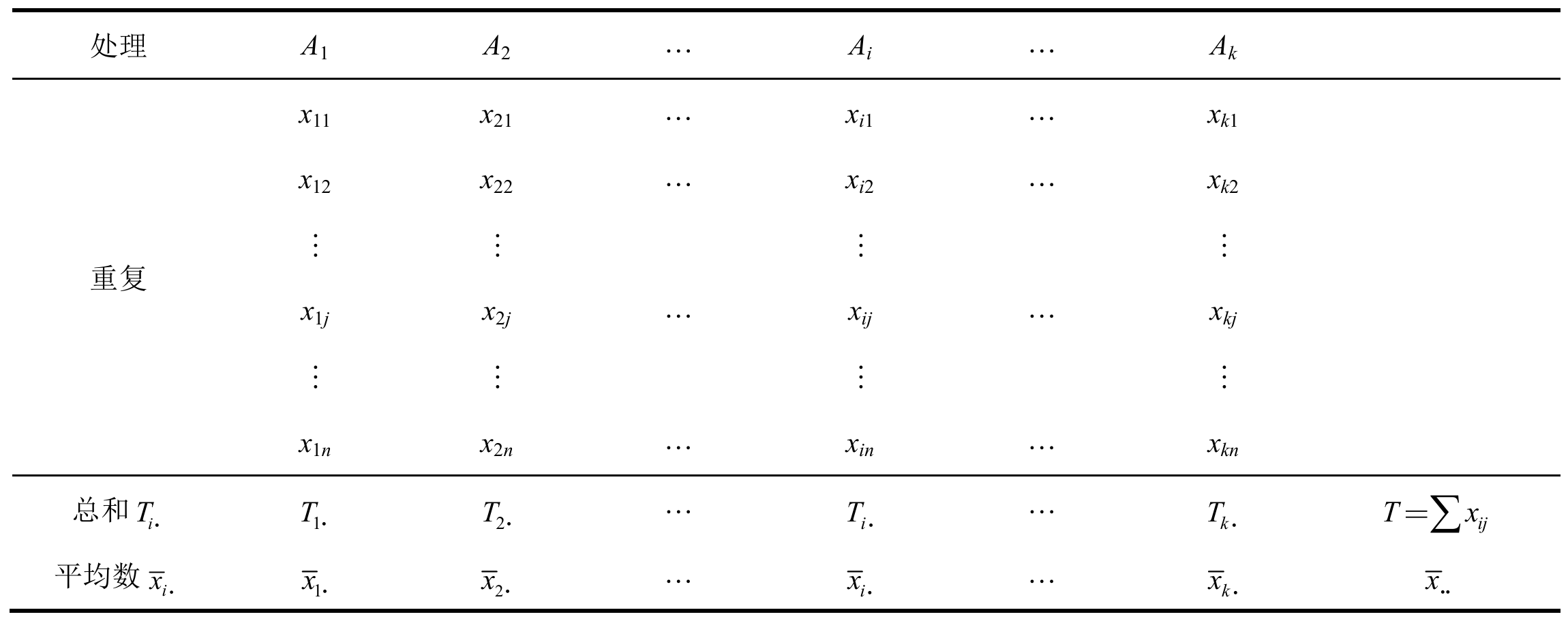
使用线性可加模型描述每一个观测值:
又有总体平均数
最后得到单因素试验数据的数学模型:
- 固定模型:各个处理的效应
是固定常量,由固定因素引起,且 。所得结论仅适用于试验的几个处理,不能扩展到未加考虑的其他水平。侧重效应值的估计与比较。 - 随机模型:效应值
是一个从正态总体 中得到的一个随机变量,试验所得不仅 ,还有 的变异程度。试验结论可以推广到随机因素的所有水平上。侧重效应方差的估计与检验。 - 混合模型:见于多因素试验,上面两种效应值的特性都存在。对于单因素试验而言,固定模型与随机模型差异不大。
基本假定
- 正态性:指试验误差应该是服从正态分布
的独立随机变量,试验数据的总体是正态总体。方差分析只能估计随机误差,。如果数据经过处理或抽取平均数据的分布都能符合正态分布条件的也可以用。 - 可加性:试验总效应中,处理效应与误差效应是可加的,服从数据的线性模型(
)。 - 方差同质性/方差齐性:不同水平试验的误差方差应该相同,具有一个共同总体方差
。方差分析前先做方差同质性检验。
平方和与自由度的分解
观测值的总变异由总体方差度量,方差由离均差平均和除自由度得到。方差分析的目的是将总变异中的处理水平变异和误差变异区分开来。需要将总平方和和总自由度分解出各变异来源的对应部分。
- 平方和分解:推导过程从略,见书P157。总平方和为组间平方和与组内误差平方和之和——
,其中 。T为所有数据之和, 。 - 自由度分解:
。
处理间方差
F检验
确定组间差异是否显著。零假设是各处理的变量来自同一个总体,人话就是组间差异跟组内差异没有区别,nk个数据共享一个正态分布,数学表达就是
若组间方差小于误差方差,则可以直接接受零假设。
定性地说,组间平方和相较于组内平方和越大,则两个变量关联越强,为了量化这种关系强弱,采用
平均数的多重比较
F检验拒绝零假设而认为组间差异显著,但无法确定任两组的差异都是显著的,也不能确定哪几个组间有显著差异。而确定具体的任两组组间差异就需要多重比较。在此介绍两种常用方法:
最小显著差数法(LSD法):实质是两个平均数比较的t检验。先计算出达到差s异显著的最小差数(
),然后用两个用于比较的组平均数差进行比较。若 则认为在给定 水平上差异显著。 在给定自由度和 后即可查表得到, 。多重比较的表示方法有标记字母法与梯形法。其中标记字母法就是将平均数由小到大排,阶梯式地比较出差异显著的组合,然后再在显著组的基础上继续往后比。梯形法又称三角形法,就是把所有平均数差放在n^2^的阵列中,只需要一半就是三角形。 “但是由于LSD法没有考虑相互比较的处理平均数依数值大小排列上的秩次,故仍有推断可靠性低、犯
错误概率(假阳性)增加的问题。”呃换个说法就是,判断标准即LSD是固定的,只取决于试验误差、重复次数和自由度,却与被比较的两个平均数在整体排序中的位置关系无关;而假阳性概率升高是因为比较次数会增加,进行大量比较时(k个处理水平就有 次两两比较),至少犯一次 错误的概率就会远超5%。同样的LSD标准容易将秩次差异大导致的偶然大差距误判为“真实”显著差异。 最小显著极差法(LSR法):给定显著水平
后,其显著差数标准会随极差范围内所包含的处理数据的秩次距( )不同而变化。有新复极差检验和 检验两类。 - 新复极差检验(SSR法):零假设为组间平均数相同。先按比较的样本容量计算平均数标准误
,根据平均数标准误的自由度 以及比较各平均数对应的秩次距 去查SSR值表得到 。判定标准为 ,判定显著性方法与前面LSD法一样。 - q检验(SNK检验):以统计数q的概率分布为基础,方法与新复极差检验类似。查的是q值表。判定标准为
。
在秩次增大时,LSR方法的显著尺度会比LSD更大,其中q检验方法的显著尺度比SSR的更大。在实际研究工作中,对于精度要求高的试验应用q法,一般试验可用SSR法,试验中各处理都与对照相比的试验数据可用LSD法。
- 新复极差检验(SSR法):零假设为组间平均数相同。先按比较的样本容量计算平均数标准误
单因素方差分析
One-way analysis of variance, one-way ANOVA。
组内观测次数相同
流程见前。
组内观测次数不同
总观测次数为
组间变异自由度
双因素方差分析
无重复观测值
两个因素,每个处理组合都只有一个观测值。观测数据构成一个表,设A因素B因素各有a、b的处理水平。其中A1因素的b个观测值的总和定为1因素的a个观测值和为
在两个因素没有互作的情况下,双因素方差分析的线性模型就是
平方和分解、自由度分解见下:
$$
\left{
\begin{array}{lr}
C=\dfrac{T^2}{ab} \
SS_T=\sum x_{ij}^2-C \
SS_A=\dfrac{\sum T_{i\cdot}^2}{b}-C \
SS_B=\dfrac{\sum T_{\cdot j}^2}{a}-C \
SS_e=SS_T-SS_A-SS_B
\end{array}
\right.
\left{
\begin{array}{lr}
df_T=ab-1\
df_A=a-1\
df_B=b-1\
df_e=(a-1)(b-1)
\end{array}
\right.
$$
两因素的联合效应强度衡量直接用
有重复观测值
为了明确是误差还是互作,需要设计重复的观测。总观测次数有abn次。在考虑单一因素A1×因素B的b个水平的b个组时,重复n次,形成一个bn大小的表。总和为1因素×因素A的a个水平的a个组时,重复n次的大小an大小的表。总和为
考虑互作的线性模型:$x_{ijk}=\mu+\alpha_i+\beta_j+(\alpha\beta){ij}+\varepsilon{ijk}
平方和分解、自由度分解见下:
$$
\left{
\begin{array}{lr}
C=\dfrac{T^2}{abn} \
SS_T=\sum x_{ijk}^2-C \
SS_A=\dfrac{\sum T_{i\cdot}^2}{bn}-C \
SS_B=\dfrac{\sum T_{\cdot j}^2}{an}-C \
SS_{AB}=\dfrac{\sum T_{ij}^2}{n}-C-SS_A-SS_B\
SS_e=SS_T-SS_A-SS_B-SS_{AB}
\end{array}
\right.
\left{
\begin{array}{lr}
df_T=abn-1\
df_A=a-1\
df_B=b-1\
df_{AB}=(a-1)(b-1)\
df_e=ab(n-1)
\end{array}
\right.
$$
是特定因素水平组的n次观测的总和
在固定模型中(
多重比较时,以因素A为例,其平均数标准误为
在互作存在时,
多因素方差分析
这里分析三因素的情况。ABC因素分别由abc水平,每一个处理组都有n次重复。总观测次数abcn,观测值有
$$
x_{ijkl}=\mu+\alpha_i+\beta_j+\gamma_k+(\alpha\beta){ij}+(\alpha\gamma){ik}+(\beta\gamma){jk}+(\alpha\beta\gamma){ijk}+\varepsilon_{ijkl}
\left{
\begin{array}{lr}
\sum\alpha_i=\sum\beta_j=\sum\gamma_k=0 \
\sum(\alpha\beta){ij}=\sum(\alpha\gamma){ik}=\sum(\beta\gamma){jk}=0 \
\sum(\alpha\beta\gamma){ijk}=0 \
\varepsilon\sim N(\mu,\sigma^2)
\end{array}
\right.
SS_T=\sum x_{ijkl}^2-\dfrac{T^2}{abcn}=SS_A+SS_B+SS_C+SS_{AB}+SS_{AC}+SS_{BC}+SS_{ABC}+SS_e
\left{
\begin{array}{lr}
df_A=a-1\
df_B=b-1\
df_C=c-1\
df_{AB}=(a-1)(b-1)\
df_{AC}=(a-1)(c-1)\
df_{BC}=(b-1)(c-1)\
df_{ABC}=(a-1)(b-1)(c-1)\
df_e=abc(n-1)
\end{array}
\right.
$$
固定模型的F检验中,分母都是
比如AB固定C随机,则AB组合变异来源的
,而AC组合就是 。 另,C变异来源就是
,B变异来源就是 。
缺失数据的估计与数据转换
缺失数据的估计方法
弥补缺失数据的原则是在补缺之后让误差平方和最小。其实就是设未知数然后求导解。
注意缺了多少个数据在补充后,进行方差分析时,总自由度和误差自由度各需减去对应数值。
数据转换
平方根处理,数据较小的时候会加一开根;对数处理;倒数处理;反正弦转换:处理数据量较小n<30的情况,数据要求以比率或百分数表示,分布趋向于二项分布,反正弦转化为角度数据(
数据转换的目的主要就是满足方差同质性,因此当平均数与组间均方有相关性或组内均方变异较大时,就需要考虑数据转换,尽量降低平均数与均方的相关性。
8-直线回归与相关分析
相关分析是两个平行关系的变量使用,两个变量均有随机误差。两个变量的相关分析是直线/简单相关,一个变量与多个变量的线性相关称为复相关分析。
直线回归分析
建立方程
y的条件平均数
SP即x以及y的离均差乘积和,又记作
由于
,故 。
回归方程必过中心点
数学模型与基本假定
总体与样本:(总体回归系数
$$
\left{
\right.
\quad
\left{
\right.
$$
基本假定:x是没有误差的固定变量,至少相较于y小到可忽略;y是随机变量;x的任一值都对应一个呈正态分布的y总体,其平均数为
假设检验
因变量的变异可以拆分成由x变异引发的变异和误差引起的变异,对应
由直线回归方程
又记作:
回归平方和的自由度为1,离回归平方和的自由度n-2,离回归方差记作
检验两个变量是否存在线性关系使用F检验,回归方差与离回归方差之比服从
检验线性回归关系是否显著使用t检验,零假设是
其实说到底t检验和F检验的检验结果应该是完全一致的,在同一概率值下,
区间估计
在确定回归关系显著后才能用样本统计数的ab来估计总体参数的
根据
, , 。 在简单线性回归模型中,
, 、 。 代入
:
将其中的记作系数 ,则 。 由于
相互独立且方差为 ( ),则a的方差为 。
故最后得到。
总体回归截距
总体回归系数
由x的任一值对应y总体的平均数
还是根据模型:
, 、 。 分解方差组成:
。 由于
,故 ; 由于
,故 ;
当时, ;当 时, 。 故
。 合并上面的结果就能得到:
用残差均方这一无偏估计代替 ,得到 的方差估计即为:
若用回归方程去预测x为某一值时y的观测值所在区间,则y观测值除了受
对于一个新的
,对应有观测值 ,而估计的回归方程预测值为 。 则单个观测值的误差为
,即回归线估计误差+个体随机变异,表示为 ,其中 ,即条件均值估计的方差。而 即方括号里多的一个1的来源。
应用与注意事项
直线相关分析
相关系数与决定系数
相关系数的假设检验
相关系数的区间估计
注意事项
- Title: Biostatistics
- Author: Kirschy
- Created at : 02-22-2025 00:00:00
- Updated at : 03-18-2026 14:24:29
- Link: https://kirschyr.github.io/2025/02/22/Biostatistics/
- License: This work is licensed under CC BY-NC-SA 4.0.